



mysql 下载:https://downloads.mysql.com/archives/community/
Proxysql 下载:https://proxysql.com/documentation/installing-proxysql/
Redis 下载:
https://redis.io/download/#redis-downloads
https://download.redis.io/releases
mongodb 官网:https://www.mongodb.com/docs/
数据库安装以及基础管理
库数据版本选择偶数为稳定版
mysql-5.7.44
mysql-8.0.36
mysql-8.4.6
1. mysql 的安装
#步骤一:下载软件程序包
https://downloads.mysql.com/archives/community/
#步骤二:准备软件应用环境
#DNS域名解析设置
echo " 10.0.0.51 db01 " >>/etc/hosts
#检查系统中是否有其他数据库服务,避免和mysql数据库服务产生冲突
rpm -qa|grep mariadb
rpm -qa|grep mysql
yum remove -y xxx / rpm -e xxx
#创建数据库服务用户增加系统安全行,并创建数据库数据存储目录
useradd -M -s /sbin/nologin mysql
mkdir -p /app/data /app/logs
chown -R mysql:mysql /app/
#步骤三:安装软件程序
tar xf mysql-8.0.36-linux-glibc2.12-x86_64.tar.xz -C /usr/local
cd /usr/local/
ln -s mysql-8.0.36-linux-glibc2.12-x86_64 mysql
echo 'export PATH="$PATH:/usr/local/mysql/bin"' >>/etc/profile
source /etc/profile
[root@centos local]# mysql -V
mysql Ver 8.0.36 for Linux on x86_64 (MySQL Community Server - GPL)
#步骤四:初始化数据库(生成数据文件):
5.5 5.6版本:
老版本环境变量:export PATH="$PATH:/usr/local/mysql/bin:/usr/local/mysql/scripts"
mysql_install_db
5.7 8.0 9.0版本:
mysqld --initialize --user=mysql --datadir=/app/data/ --basedir=/usr/local/mysql
选项说明:
--initialize 安全初始化,初始化时会生成一个临时密码
--initialize-insecure 表示不安全方式初始化(无管理员密码)
--user 管理数据库用户
--datadir 指定数据目录
--basedir 数据库安装路径
#初始化后会生成临时密码,记得先保存:
[root@kylin data]# mysqld --initialize --user=mysql --datadir=/app/data --basedir=/usr/local/mysql
2025-12-18T03:27:07.647664Z 0 [System] [MY-013169] [Server] /usr/local/mysql-8.0.36-linux-glibc2.12-x86_64/bin/mysqld (mysqld 8.0.36) initializing of server in progress as process 267656
2025-12-18T03:27:07.659705Z 1 [System] [MY-013576] [InnoDB] InnoDB initialization has started.
2025-12-18T03:27:08.064632Z 1 [System] [MY-013577] [InnoDB] InnoDB initialization has ended.
2025-12-18T03:27:10.166213Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: Qdwpi0pZuI,v
#初始化失败怎么操作:
1.检查初始化语句是否正确,找出错误原因
2.删除数据目录下内容(例如:\rm -rf /app/data/*)
3.重新初始化
#步骤五:编写数据库配置文件
cat >/etc/my.cnf<<EOF
[mysqld]
port=3306
user=mysql
datadir=/app/data
basedir=/usr/local/mysql
socket=/tmp/mysql.sock
EOF
#步骤六:启动数据库
#mysql自带启动脚本
ls -l /usr/local/mysql/support-files/mysql.server
# 设置数据库服务程序启动运行文件
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
#启动
/etc/init.d/mysqld start
#登录数据库
mysql -uroot -p
Qdwpi0pZuI,v #这是我生成的临时密码,你需要查看你的
#重置密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Oldboy101.';
FLUSH PRIVILEGES; # 刷新权限
红帽类:vim /usr/lib/systemd/system/mysqld.service
#Debian类:vim /etc/systemd/system/mysqld.service
[Unit]
Description=MySQL Server
After=network.target
[Service]
User=mysql
Group=mysql
Type=forking
ExecStart=/etc/init.d/mysqld start
ExecReload=/etc/init.d/mysqld restart
ExecStop=/etc/init.d/mysqld stop
PrivateTmp=true
[Install]
WantedBy=multi-user.target
#重新加载配置文件
sudo systemctl daemon-reload
systemctl enable mysqld
systemctl start mysqld2. 数据库密码管理
Mysql8.0 之前的默认密码认证插件为:mysql_native_password
8.0 开始数据库的密码加密插件为:caching_sha2_password
caching_sha2_password 解决了 mysql_native_password 的两大问题:
● 安全性:SHA256 加密强度远高于 SHA1,符合现代安全规范;
● 性能:自带缓存机制,减少重复加密计算,认证效率更高。
修改密码插件:
方法一:创建用户过程修改加密插件信息
create user xaiobai@'localhost' identified with mysql_native_password by '123456';
select user,host,authentication_string,plugin from mysql.user;
方法二:修改已经创建用户加密插件信息
alter user 'xiaobai'@'10.0.0.%' identified with mysql_native_password by '123456';
select user,host,authentication_string,plugin from mysql.user;
方法三:修改数据库服务配置文件信息(全局修改)
# 编辑 MySQL 配置文件 /etc/my.cnf
vim /etc/my.cnf
# 添加以下配置
[mysqld]
default_authentication_plugin = mysql_native_password
# 重启 MySQL 服务生效
systemctl restart mysqld数据库设置密码:
方法一:在数据库外,命令行中
mysqladmin -uroot -password "123456"
方法二:在数据库中
alter user 'root'@'localhost' identified by '123456'
数据库修改密码:
直接命令行修改:
mysqladmin -uroot -p旧密码 -password '新密码'
进入数据库修改:
mysqladmin -uroot -password "旧密码"
alter user 'root'@'localhost' identified by '新密码'
数据库密码重置:
关闭数据库服务(业务低谷时)
/etc/init.d/mysqld stop
免密启动数据库服务
mysqld_safe --skip-grant-tables --skip-networking --user=mysql &
备用:# mysqld --skip-grant-tables --skip-networking --user=mysql &
说明:
-- skip-grant-tables 表示忽略授权表启动
-- skip-networking 忽略网络通讯方式启动
重置管理用户的密码
#01 进入数据库
root -uroot
#02 刷新权限(必须先执行,否则ALTER USER会报错)
FLUSH PRIVILEGES;
#03 重置密码(替换 NewMySQLPass@123 为你的新密码,需符合强度)
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Oldboy101.';
# 若需要允许远程登录(可选,生产环境谨慎)
# UPDATE user SET host='%' WHERE user='root' AND host='localhost';
#04 再次刷新权限
FLUSH PRIVILEGES;
重新恢复数据库服务
/etc/init.d/mysqld restart
进行重置密码的测试
mysql -uroot -pOldboy101.
3. 数据库用户管理
创建用户:create user 用户名@'白名单地址' identified by '密码';
白名单地址:允许哪个网段的 IP 地址连接(本地:localhost)
例如:create user xiaobai@'10.0.0.%' identified bt '123456';
查看所有用户信息:select user,host,authentication_string from mysql.user;
查看当前用户信息:select user();
删除用户:drop/delete(只有管理员权限,可以删除指定用户)
drop user 用户名@'白名单地址';
例如:drop user 'xiaoA'@'localhost';
#按条件删除用户
delete from mysql.user where user='xiaoA';
delete from mysql.user where host='主机白名单';
4. 数据库权限管理
查看数据库中所有权限信息:show privileges;
授予用户权限:grant 权限 on 赋予对象(库.表) to 权限赋予用户信息
例如:grant creat,drop on . to xiaobai@'localhost';
查询用户权限信息:show grants for 用户@白名单地址;
例如:show grants for xiaobai@localhost;
撤销用户权限:revoke 撤销的权限信息(多个权限用逗号分隔) on 撤销权限对象信息(库.表)from 权限撤销的用户信息(用户名@'白名单');
例如:revoke create,drop on . from xiaobai@'localhost';
特殊权限:
a. 将数据库所有权限赋予某个用户(需要管理员操作)
grant all on 库.表 to 用户名@'白名单';
b. 让其用户可以授予其它用户权限(只能授予自己有的权限)
grant grant option on 库.表 to 用户名@'白名单';
grant 权限 on 库.表 to 用户名@'白名单' with grant option;
c. 只能连接数据库的权限(新用户的默认权限)Usage
例如:GRANT USAGE ON . TO 'xiaobai'@'10.0.0.%';
-- 步骤1:创建用户
CREATE USER '用户名'@'主机地址' IDENTIFIED BY '用户密码';
-- 步骤2:授予Usage权限
GRANT USAGE ON . TO '用户名'@'主机地址';
查看授权表权限信息
---------------------------------------------------------------------------
mysql.user:记录全局级权限(对所有数据库生效)
mysql.db:记录数据库级权限(仅对指定数据库生效)
mysql.tables_priv:记录表级权限(仅对指定数据库的指定表生效)
举个栗子:
create user test01@'localhost';
create user test02@'localhost';
create user test03@'localhost';
grant select,insert,update,delete on . to test01@'localhost';
grant select,insert,update on test01.* to test02@'localhost';
GRANT CREATE ON . TO 'test03'@'localhost';
test03 用户:
create table t1 (id int);
use test01;
create table t1 (id int);
grant select,insert on test01.t1 to test03@'localhost';
查看mysql.user表:
mysql> select * from mysql.user where user='test01'\G
*************************** 1. row ***************************
Host: localhost
User: test01
Select_priv: Y
Insert_priv: Y
Update_priv: Y
Delete_priv: Y
mysql> select * from mysql.db where user='test02'\G
*************************** 1. row ***************************
Host: localhost
Db: test01
User: test02
Select_priv: Y
Insert_priv: Y
Update_priv: Y
mysql> select * from mysql.tables_priv where user='test03'\G
*************************** 1. row ***************************
Host: localhost
Db: test01
User: test03
Table_name: t1
Grantor: root@localhost
Timestamp: 2025-12-19 10:17:46
Table_priv: Select,Insert
---------------------------------------------------------------------------
5. 数据库服务配置管理(配置方法)
1.默认自动加载方式
将命名为my.cnf(或.my.cnf)的配置文件,放到 MySQL 默认扫描的路径中,数据库服务启动时会自动加载这些路径下的配置文件。
默认扫描路径(按优先级排序,前面的会覆盖后面的):
/etc/my.cnf
/etc/mysql/my.cnf
/usr/local/mysql/etc/my.cnf
~/.my.cnf(当前用户家目录下的隐藏文件)
例如:
mkdir -p /etc/mysql
/etc/init.d/mysql stop
mv /etc/my.cnf /etc/mysql/
/etc/init.d/mysql start
#也会自动寻找并加载这个路径下的配置文件,数据库也可以正常使用。
2.自定义加载方式
a.(临时生效)直接在启动mysqld或mysqld_safe服务时,通过--defaults-file参数指定配置文件路径,示例:
# 启动MySQL并加载/tmp/my.cnf配置文件(&表示后台运行)
mysqld --defaults-file=/tmp/my.cnf &
# 或用mysqld_safe启动
mysqld_safe --defaults-file=/tmp/my.cnf &
b.可以编写 systemd 的 service 文件加载(永久生效)
vim /etc/systemd/system/mysqld.service
[Unit]
Description=MySQL Server # 服务描述
Documentation=man:mysqld(8)
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target # 依赖网络服务启动
After=syslog.target
[Install]
WantedBy=multi-user.target # 多用户模式下启动
[Service]
User=mysql # 运行MySQL的用户
Group=mysql # 运行MySQL的用户组
# 启动命令中指定自定义配置文件路径
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/tmp/my.cnf
LimitNOFILE=5000 # 限制文件打开数
systemctl daemon-reload
systemctl restart mysqld如何编写配置文件(方法规则)
-- 需要指定编写标签
客户端标签 [client][mysql][mysqladmin][mysqldump]
作用:简化客户端命令参数应用
服务端标签 [server][mysqld][mysqld_safe]
作用:可以实现数据库服务启动/实现数据库服务功能应用
-- 合理编写标签下的配置项信息(确认配置项变量名和值都要正确)
mysql --help |grep '配置项变量' -- 确认配置项是否合理
mysqld --help --verbose|grep '配置项变量' -- 确认配置项是否合理
6. 数据库服务连接管理(多实例搭建)
方式一:利用socket建立远程连接(unix 套接字文件连接)
利用此方法建立数据库服务的连接,只能用于建立本地数据库服务的连接;
说明:需要在数据库服务中授权localhost用户,才能实现采用socket方式登录操控数据库服务
# 套接字文件信息定义:
[root@db01 ~]# cat /etc/my.cnf
[mysqld]
socket=/tmp/mysql.sock
-- 指定数据库服务加载的套接字文件路径信息
# 利用套接字文件建立数据库服务连接
[root@db01 ~]# mysql -uroot -poldboy123 -S /tmp/mysql.sock
-- -S指定socket的信息可以省略,因为在数据库服务配置文件的客户端已经配置过了
方式二:利用TCP/IP建立远程连接(网络地址与端口)
说明:需要在数据库服务中授权网络白名单用户,才能实现采用TCP/IP方式登录操控数据库服务
# 利用TCP/IP建立数据库服务连接
[root@db01 ~]# mysql -uroot -p123456 -h 10.0.0.101 -P3306 -S /var/lib/mysql/mysql.sock
--------------------------------------------------
经典套接字错误:
[root@kylin ~]# mysql -u root -p
Enter password:
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
原因:
1)就是socket信息配置调整了,连接时没有正确使用套接字文件
2)数据库服务没有正确启动
解决:
# 编辑mysqld服务配置(如果服务名是mysql,就改mysql.service)
systemctl edit mysqld.service
[Service]
PrivateTmp=no
systemctl daemon-reload
systemctl restart mysqld
--------------------------------------------------
方法一:利用数据库程序客户端命令连接(本地/远程)
[root@db ~]# mysql -uroot -p123456
-- 以上连接方式等价于,以下长格式命令登录方式
[root@db ~]# mysql -uroot -p123456 -hlocalhost -P3306 -S /var/lib/mysql/mysql.sock
--- 进行本地连接时,hlocalhost -P3306 -S /var/lib/mysql/mysql.sock可以省略
# 远程连接数据库服务:
[root@db ~]# mysql -uroot -p123456 -h10.0.0.101 -P3306 -S /var/lib/mysql/mysql.sock
mysql -- 数据库客户端管理命令
mysqladmin -- 数据库功能设置操作(密码设置 关闭操作)
mysqldump -- 数据库服务备份功能
方法二:利用工具连接管理数据库(图形界面 管理数据库更简单方便)
https://worktile.com/kb/p/2828683
下载工具后,创建远程登陆用户并授权
create user root@'10.0.0.%' identified by '123456';
grant all on *.* to root@'10.0.0.%' with grant option;
方法三: 利用程序代码+连接器
针对开发人员需要开发程序连接后端数据库
什么是多实例:一般在一个系统环境中,可以运行多个相同的服务程序信息,并且产生不同的进程和网络端口信息,就可以称为多实例概念
多实例作用:
1)资源隔离和性能优化:
- 避免资源争抢:
不同的 MySQL 实例可以分配不同的 CPU 核心、内存等资源,避免实例之间相互影响,提高整体性能。
例如,一个实例用于在线业务,一个实例用于数据分析,避免相互干扰。
- 提升性能隔离:
不同应用的数据可以分散到不同的实例上,有效控制单个实例的数据量。
这样可以减少查询和维护操作的影响,提高每个实例的响应速度和稳定性。
2)应用隔离和安全性:
- 不同应用隔离:
将不同的应用数据存储在不同的实例中,可以防止一个应用出现故障影响到其他应用。
- 改善安全隔离:
不同的实例可以使用不同的用户权限管理策略,增强数据的安全性。例如,敏感数据和非敏感数据分别存储在不同的实例中。
- 测试和开发环境隔离:
可以快速创建新的实例用于测试和开发,而不会影响到生产环境。
3)高可用性和容错性:
- 故障隔离:
一个实例发生故障不会影响到其他实例的正常运行。
- 快速切换:
通过配置主备实例,可以在主实例发生故障时快速切换到备实例,保证服务的连续性。
- 读写分离:
多个实例可以配合使用,实现读写分离架构,提高数据库的并发处理能力。
其中一个实例作为主库负责写入,其他的实例作为从库负责读取。
4)版本管理和升级:
- 平滑升级:
可以先升级一个实例,验证新版本的功能和稳定性,再逐步升级其他实例,降低升级风险。
- 不同版本的共存:
可以在同一台服务器上运行不同版本的 MySQL,满足不同应用的需求。
5)简化管理和维护:
- 批量操作:
可以使用一些工具批量管理多个实例,例如批量启动、停止、备份等。
使用场景示例:
大型网站应用: 为了提高性能和可用性,可以将用户数据、商品数据、订单数据等分别存储在不同的实例中。
数据分析平台: 可以将在线业务和数据分析业务的数据存储在不同的实例中,避免数据分析操作影响在线业务的性能。
开发测试环境: 可以为每个开发人员或测试项目创建一个独立的实例,方便测试和调试。
创建多实例的注意事项:
资源规划: 要合理规划服务器的 CPU、内存、磁盘等资源,确保每个实例都有足够的资源运行。
端口配置: 每个实例必须配置不同的端口号,避免端口冲突。
配置管理: 要分别管理每个实例的配置文件,确保配置正确。
监控告警: 要建立完善的监控和告警机制,及时发现和处理问题。
总而言之,MySQL 创建多实例是一个重要的管理和优化技术,可以提高数据库的性能、可用性、安全性和可维护性。
通过根据实际需求合理创建和配置多实例,可以更好地满足不同应用的需求。
多实例配置:
步骤一:安装数据库服务程序与环境规划
省略-- 8.0.36
| 实例信息编号 | 实例服务端口 | 实例存储路径 | 实例配置文件 | 套接字文件 |
| ------------ | -------------- | --------------- | ---------------------- | ------------------- |
| mysql-01 | 端口信息:3306 | /data/3306/data | /data/3306/data/my.cnf | /tmp/mysql3306.sock |
| mysql-02 | 端口信息:3307 | /data/3307/data | /data/3307/data/my.cnf | /tmp/mysql3307.sock |
| mysql-03 | 端口信息:3308 | /data/3308/data | /data/3308/data/my.cnf | /tmp/mysql3308.sock |
步骤二:创建多实例数据目录
mkdir -p /data/330{6..8}/data && chown -R mysql:mysql /data
步骤三:进行数据库服务初始化
mysqld --initialize-insecure --user=mysql --datadir=/data/3306/data --basedir=/usr/local/mysql
mysqld --initialize-insecure --user=mysql --datadir=/data/3307/data --basedir=/usr/local/mysql
mysqld --initialize-insecure --user=mysql --datadir=/data/3308/data --basedir=/usr/local/mysql
步骤四:编写生成配置文件
3306-my.cnf
cat >/data/3306/my.cnf <<EOF
[mysqld]
user=mysql
port=3306
datadir=/data/3306/data
basedir=/usr/local/mysql
socket=/tmp/mysql3306.sock
EOF
#3307-my.cnf配置文件
cat >/data/3307/my.cnf <<EOF
[mysqld]
user=mysql
port=3307
datadir=/data/3307/data
basedir=/usr/local/mysql
socket=/tmp/mysql3307.sock
EOF
#3308-my.cnf配置文件
cat >/data/3308/my.cnf <<EOF
[mysqld]
user=mysql
port=3308
datadir=/data/3308/data
basedir=/usr/local/mysql
socket=/tmp/mysql3308.sock
EOF
步骤五:将每个数据库实例运行启动
mysqld --defaults-file=/data/3306/my.cnf &
mysqld --defaults-file=/data/3307/my.cnf &
mysqld --defaults-file=/data/3308/my.cnf &
cat >/etc/systemd/system/mysqld3306.service <<EOF
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/data/3306/my.cnf
LimitNOFILE=5000
EOF
cat >/etc/systemd/system/mysqld3307.service<<EOF
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/data/3307/my.cnf
LimitNOFILE=5000
EOF
cat >/etc/systemd/system/mysqld3308.service<<EOF
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/data/3308/my.cnf
LimitNOFILE=5000
EOF
systemctl daemon-reload
systemctl restart mysqld3306 mysqld3307 mysqld3308
systemctl status mysqld3306 mysqld3307 mysqld3308数据库服务基础语句应用
1. 数据库服务语句类型
数据库服务中,对数据库数据或功能做管理,需要应用SQL语句
DDL Data Definition Language(数据定义语言)
作用:主要用于多数据库 数据表 索引信息对象做设置管理功能
create alter drop
? Data Definition 获取详细DDL语句信息
DCL Data Control Language(数据控制语言)
作用:可以管理数据用户和权限相关信息(安全性)
grant revoke ALTER USER
? Account Management
DML Data Manipulation Language(数据操作语言)
作用:主要用于管理数据表中的数据信息
insert update delete
? Data Manipulation
DQL Data Query Language(数据查询语言)
作用:表示可以查询数据库中数据信息和配置信息
select show 1.1. 操作结构(DDL):定义 / 修改 / 删除数据库对象(结构级操作)
核心作用:创建、修改、删除数据库、表、视图、索引等对象,会改变数据库的结构,执行后通常自动提交事务。
1.2. 操作权限(DCL):管理用户 / 权限 / 资源组(权限级操作)
核心作用:控制数据库的访问权限、用户管理、资源分配,决定谁能访问 / 操作数据库对象。
1.3. 操作数据(DML):操作数据库中的数据(增删改查 / 导入导出)
核心作用:仅修改数据内容,不改变数据库 / 表的结构,是日常使用最频繁的语句。
1.4. 特殊 / 辅助语句:非核心分类的特殊执行语句
核心作用:执行存储过程、处理表数据、导入表等特殊场景,不属于 DML/DDL/DCL 核心分类。
2. 数据库服务字符编码
字符集设置作用:可以避免中文信息乱码
校对规则设置: 可以在查询数据时是否忽略大小写/数据信息排序
一般数据库服务中,常规使用的字符集编码为utf8、utf8mb4
utf8和utf8mb4之间有什么区别?
· utf8最多存储3字节长度字符
· utf8mb4最多存储4字节长度字符(表情字符emoji)
01 查看字符编码信息
show charset;
# 查看数据库默认字符编码
show variables like "%character%";
02 修改字符编码信息
方式一:全局设置
cp /etc/my.cnf{,.bak}
vim /etc/my.cnf
[server]
character-set-server=utf8mb4 #设置服务端字符集编码为utf8mb4
方式二:指定数据库设置
create database xiaoA CHARACTER SET gbk;
alter database xiaoB CHARACTER SET gbk;
方式三:数据库字符编码信息修改
create table xiaoA (id int,name char(5)) CHARACTER SET gbk;
alter table xiaoB CHARACTER SET gbk; #不严谨的方法,只会影响之后存储的数据,不会修改之前存储的数据
03 查看设置后的字符集信息
select @@character_set_server;
show create database xiaoA;
show create table t1;3. 数据库服务数据类型
3.1. 类型一:整数数据类型
只允许指定数据列,录入的数据信息为正整数或负整数;
3.2. 类型二:浮点数据类型(小数)
理解:
设一个字段定义为float(6,3),如果插入一个数123.45678,实际数据库里存的是123.457,总个数以实际为准,即6位,整数部分最大是3位;
如果插入数12.123456,存储的是12.1234,如果插入12.12,存储的是12.1200.
浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值:decimal(m,d)
3.3. 类型三:字符串数据类型
char类型和varchar类型对比:
char(n) 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉。所以char类型存储的字符串末尾不能有空格,varchar不限于此;
char(n) 固定长度,char(4)不管是存入几个字符,都将占用4个字节,varchar是存入的实际字符数+1个字节,;
char类型的字符串检索速度要比varchar类型的快。
varchar类型和text类型对比:
varchar可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节,text是实际字符数+2个字;
text类型不能有默认值;
varchar可直接创建索引,text创建索引要指定前多少个字符。varchar查询速度快于text,在都创建索引的情况下。
3.4. 类型四:时间数据类型
若定义一个字段为timestamp,这个字段里的时间数据会随其他字段修改的时候自动刷新,所以这个数据类型的字段可以存放这条记录最后被修改的时间。
4. 数据库服务约束属性(数据存储合理性)
限制属性,避免录入数据信息混乱,避免输入重复与输入数据信息不能为空等
4.1. 常见的约束:
USE xiaoA;
CREATE TABLE student (
-- PK主键约束:学号id,非空且唯一(表的唯一标识)
id INT PRIMARY KEY COMMENT 'PK约束:学生学号,非空且唯一',
-- NN非空约束:姓名不能空
name VARCHAR(50) NOT NULL COMMENT 'NN约束:学生姓名,必须填写',
age TINYINT,
-- UQ唯一约束:手机号不能重复(但可以为空)
phone VARCHAR(11) UNIQUE COMMENT 'UQ约束:学生手机号,不能重复'
);主键约束可以设置多列吗?
答:主键约束确实可以设置在多列上(这种主键叫「复合主键 / 联合主键」),
但在实际开发中几乎都不推荐使用,只有极少数特殊场景例外。
什么是复合主键?
答:就是把多个字段组合起来作为表的主键,
比如 “学生选课表”,如果用「学生 ID + 课程 ID」一起作为主键,
就能保证 “同一个学生不能重复选同一门课”(因为组合值唯一)。
为什么不推荐用复合主键?
1. 可读性差,关联麻烦
复合主键是多列组合,后续关联其他表时(比如选课表关联成绩表),
需要同时带上所有主键列(student_id + course_id),
而不是只用一个字段,代码和 SQL 会变复杂,新手容易漏写、写错。
2. 扩展成本高
比如后续想给选课表加 “选课批次”(同一学生同一课程不同批次可重复选),
复合主键就需要新增列,修改主键结构会影响所有关联表,风险极高。
3. 不符合 “主键无业务意义” 的最佳实践
好的主键应该是「与业务无关的自增 ID」(比如id INT AUTO_INCREMENT PRIMARY KEY),
而复合主键通常绑定业务字段(学生 ID、课程 ID),业务规则变了,主键也要改。
4. 部分数据库 / 框架兼容问题
很多 ORM 框架(比如 MyBatis、JPA)对复合主键的支持不友好,
需要额外写复杂的映射关系,增加开发成本。
复合主键的替代方案?
答:单字段自增主键 + 唯一约束
例如:
CREATE TABLE student_course (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '选课记录ID',
student_id INT NOT NULL COMMENT '学生ID',
course_id INT NOT NULL COMMENT '课程ID',
score INT COMMENT '成绩',
-- 用唯一约束保证“学生+课程”组合唯一,效果和复合主键一样
UNIQUE KEY uk_student_course (student_id, course_id)
);
这个方案的好处?
主键(id)简单唯一,关联其他表时只用这一个字段;
唯一约束(uk_student_course)保证业务规则(同一学生不重复选同一课程);
后续扩展(加选课批次)只需修改唯一约束,不用动主键,成本极低。
4.2. 常见的属性:
USE xiaoA;
CREATE TABLE student (
id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY COMMENT '学生学号,自增非负主键',
name VARCHAR(50) NOT NULL COMMENT '学生姓名,非空',
age TINYINT UNSIGNED COMMENT '学生年龄,只能存非负数',
gender VARCHAR(10) DEFAULT '未知' COMMENT '学生性别,默认值为未知'
);
default: 给字段设默认值,没填就自动用;
auto_increment:数值主键自动编序号,不用手动写;
comment: 给字段加 “备注”,方便人理解,不影响数据;
unsigned: 数值字段 “禁负数”,既保证数据合理,又能扩大取值范围。数据库服务扩展语句应用
结构操作语句-DDL
管理数据库本身创建、删除数据库,切换数据库等。
管理表结构创建表、修改表(增删字段、改字段类型)、删除表。
管理约束 / 索引给表添加 / 删除主键、唯一约束、非空约束,以及创建 / 删除索引。
创建数据库-create
create database 库名;
create schema 'xiaobai';
create schema 'xiaobai' default character set gbk;
注意:创建的数据库名称要有效合理,数据库名称在后期无法进行修改调整
查看库语句-show
show databases; -- 查看所有数据库信息
show databases like 'xiao%'; -- 数据库%等价于正则符号 .*
show databases like 'xiao_'; -- 数据库_等价于正则符号 .
show create database xiaoB; -- 查看数据库完整的创建语句
修改库语句-alter database
alter database 库名 CHARACTER SET utf8mb4;
删除库语句-drop database
1.逻辑删除数据库(数据目录一并会删除)
drop database 库名
注意: 需要删除任何数据库前,请和相关负责人做好文字确认
2.物理删除数据库(直接删除数据库目录)知道即可 不要使用
rm -rf /data/3306/data/xiaoA
练习:
在xiaoA库中创建一个学生表,包含学号 姓名 年龄 性别列信息,并且学号列为主键列 姓名非空 年龄非负 性别默认值为“未知”;
use xiaoA
CREATE TABLE student (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` VARCHAR(10) NOT NULL COMMENT '姓名',
`age` TINYINT UNSIGNED NULL COMMENT '年龄',
`gender` ENUM('男', '女', '未知') NOT NULL DEFAULT '未知' COMMENT '性别',
PRIMARY KEY (`id`));
查看数据表-show/desc
show tables; -- 切换到指定数据库,查看所有表信息
show tables from xiaoA; -- 利用from指令查看指定库下所有表信息
desc 表名; -- 查看指定表结构信息(可以熟悉所管理的表)
desc xaioA.student;
+--------+----------------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+----------------------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(10) | NO | | NULL | |
| age | tinyint unsigned | YES | | NULL | |
| gender | enum('男','女','未知') | NO | | 未知 | |
+--------+----------------------------+------+-----+---------+----------------+
show create table 表名; -- 获取完整的创建表语句
修改数据表-alter table
1.修改数据表名称
rename table 源表名 to 新表名;
alter table 源表名 rename 新表名;
2.修改表结构信息
添加新字段
ALTER TABLE student ADD COLUMN class VARCHAR(45) NULL AFTER `gender`;
ALTER TABLE student ADD COLUMN class VARCHAR(45) NOT NULL FIRST;
修改字段信息
ALTER TABLE student CHANGE COLUMN gender ssex ENUM('男', '女', '未知') NOT NULL DEFAULT '未知' COMMENT '性别' ;
删除字段信息
ALTER TABLE student DROP COLUMN ssex;
3.修改表的数据类型/约束属性信息
ALTER TABLE student CHANGE COLUMN name CHAR(10) NOT NULL COMMENT '姓名' ;
ALTER TABLE student ADD UNIQUE INDEX `name_UNIQUE` (`name` ASC) VISIBLE;
ALTER TABLE student CHANGE COLUMN name CHAR(10) NULL COMMENT '姓名' ;
PS:对表中数据类型或者约束属性信息修改,需要根据数据情况修改
删除数据表
1.删除表和数据
drop table 表名;
2.清空表数据
delete from 表名; -- 删除效率慢(指定数据删除)
truncate table 表名; -- 删除效率快
数据操作语句-DML
新增数据:往表中插入新的记录
查询数据:从表中获取需要的记录
修改数据:更新表中已有的记录
删除数据:移除表中不需要的记录
增加数据内容信息(insert)
# 数据表数据插入命令语法
mysql> insert into <表名> [( <字段名1>[,..<字段名n > ])] values ( 值1 )[, ( 值n )];
-- 属于表内容信息变更操作,需要按照表结构预先定义好的字段信息插入
具体实际操作过程:
mysql> desc stu1;
mysql> insert into stu1(id,name,age,dept) values(1,'oldboy',35,'net sec');
-- 插入单行信息标准方法(信息输入不要重复,且特定信息不要为空)
mysql> insert into stu1(id,name,age,dept) values(0,'oldboy',35,'net sec');
mysql> insert into stu1(id,name,age,dept) values(null,'oldboy',35,'net sec');
-- 插入单行信息标准方法(自增列信息可以填入0或null,表示默认实现自增效果)
mysql> insert into stu1 values(2,'oldgirl',25,'linux');
-- 插入单行信息可以不含有表字段信息
mysql> insert into stu1 values(03,'littlegirl',2,'net sec'),(04,'littleboy',1,'Linux');
-- 插入多行信息可以不含有表字段信息
mysql> insert into stu1(name,age) values('oldboy',35);
-- 插入当行信息可以只含部分字段信息,但是省略字段信息必须具有自增特性 或 可以为空 或有默认值输入
mysql> insert into stu1 values(6,'老男孩',32,'python,linux,net sec');
-- 插入中文信息
# 检查信息是否插入成功
mysql> select * from stu1;
------------------------------------------------------------
修改数据内容信息(update)
# 数据表数据修改命令语法
mysql> update 表名 set 字段=新值,… where 条件;
-- 属于表内容信息变更操作,需要按照表结构预先定义好的字段信息修改,并且按照条件修改,默认全表修改
具体实际操作过程:
mysql> update stu1 set name="zhangsan" where id=6;
-- 修改表数据内容标准方式,修改时一定要加条件信息(条件信息建议为主键或具有唯一性信息)
# 检查信息是否修改成功
mysql> select * from stu1;
---------------------------------------------------------
删除数据内容信息(delete)
# 数据表数据删除命令语法
mysql> delete from 表名 where 表达式;
-- 属于表内容信息变更操作,需要按照表结构预先定义好的字段信息删除,并且按照条件删除,默认全表删除
具体实际操作过程:
mysql> delete from stu1 where id=6;
mysql> delete from stu1 where id<3;
mysql> delete from stu1 where age=2 or age=1;
mysql> delete from stu1;
-- 删除表信息时,如果不加条件会进行逐行删除全表信息(效率比较慢)
# 检查信息是否删除成功
mysql> select * from stu1;
-----------------------------------------------------------
数据查询语句-DQL
mysql官方提高查询练习的测试数据信息:https://dev.mysql.com/doc/index-other.html
#准备操作
从测试数据链接下载world测试数据并导入数据库
mysql -uroot -p -S /tmp/mysql3306.sock <world-db-测试数据/world.sql
登录:mysql -uroot -p -S /tmp/mysql3306.sock
mysql> use world;
mysql> select * from city limit 10;
+----+----------------+-------------+---------------+------------+
| ID | Name | CountryCode | District | Population |
+----+----------------+-------------+---------------+------------+
| 1 | Kabul | AFG | Kabol | 1780000 |
| 2 | Qandahar | AFG | Qandahar | 237500 |
| 3 | Herat | AFG | Herat | 186800 |
| 4 | Mazar-e-Sharif | AFG | Balkh | 127800 |
| 5 | Amsterdam | NLD | Noord-Holland | 731200 |
| 6 | Rotterdam | NLD | Zuid-Holland | 593321 |
| 7 | Haag | NLD | Zuid-Holland | 440900 |
| 8 | Utrecht | NLD | Utrecht | 234323 |
| 9 | Eindhoven | NLD | Noord-Brabant | 201843 |
| 10 | Tilburg | NLD | Noord-Brabant | 193238 |
+----+----------------+-------------+---------------+------------+
查询方法1:全表数据信息查看
select * from 库名.表名;
select 字段1,字段2 from 库名.表名;
注意:在企业中,避免使用全表查询,信息量较多的表会使负载升高
查询方法2:过滤查询数据信息
select */字段 from 库名.表名 where 条件信息
条件信息定义01:等值查询(=)
select * from city where countrycode='CHN';
条件信息定义02:范围查询(< <= > >= !=/<>)
select * from city where population>10000000;
条件信息定义03:模糊查询(like +正则%)
select * from city where name like 'xiao%';
条件信息定义04:多条件逻辑关联查询(and or not)
and:表示并且 做多次数据信息过滤,将多次过滤结果输出
or: 表示或者 根据条件对数据表分别做过滤,将过滤的结果进行整合
select * from city where countrycode='chn' and population>5000000;
练习题:
将美国大于500万人口城市和印度大于500万人口城市都查询出来(一条语句查询)
select * from city where (countrycode='USA' or countrycode='IND') and population>5000000;
条件信息定义05:多个查询条件特殊关联方式
查询全球范围内,人口数量大于300w小于500w城市信息
select * from city where population>3000000 and population<5000000;
select * from city where population between 3000000 and 5000000;
查询中国和美国的城市信息
select * from city where countrycode='chn' or countrycode='USA';
select * from city where countrycode in ('chn','USA');
select * from city where countrycode not in ('chn','USA');
条件信息定义06:查询某个列是否存在空值/查询非空值信息
select * from city where name IS NULL;
select * from city where name IS not NULL;
条件信息定义07:去重查询统计数据信息
获取中国省份数量信息
Distinct -- 对指定列做去重操作
count() -- 统计个数
select COUNT(DISTINCT District) AS province_count from city where countrycode='chn';
查询方法3:分组过滤查询数据信息
分组查询数据原理机制:
1)需要根据指定分组的列进行数据排序
2)将分组后相同信息做合并处理
3)会应用聚合函数分析分组后的数据
(count计数统计 sum求和 avg平均值 max最大值 min最小值 group_concat将多行整合为一行)
4)调取输出信息时,要确保分组列和输出列有一对一的关联关系
利用城市表,统计分析每个国家的人口总数
select countrycode,sum(population) from city group by countrycode;
利用城市表, 统计分析每个国家的城市数量,并显示城市信息
select countrycode,count(name),group_concat(name) from city group by countrycode;\G
统计中国境内,每个省份有多少城市信息,以及显示城市名称(省份列 城市数量 城市名称)
select district,count(name),group_concat(name) from city where countrycode='chn' group by district;\G
统计中国境内,每个省份有人口数量总和;(省份列 人口总和)
select district,sum(population) from city where countrycode='chn' group by district;\G
统计中国境内,每个省份有人口数量总和,并将人口数量大于50w省份信息显示输出;
select District,sum(population) from world.city where countrycode='chn' group by District having sum(population)>500000;
查询方法4:排序查询数据信息
利用城市表,统计分析每个国家的人口总数,并将城市人口排序
升序:
select countrycode,sum(population) from city group by countrycode order by sum(population);
降序:
select countrycode,sum(population) from city group by countrycode order by sum(population) desc;
查询方法5:截取数据信息查询
limit m,n (从第m行截取到第n行结束,默认0是从第1行开始)
limit m offset n (m表示截取几行信息,n表示从第几行开始截取)
利用城市表,统计分析每个国家的人口总数,并将城市人口降序,取前5行
select countrycode,sum(population) from city group by countrycode order by sum(population) desc limit 5;
-----------------------------------------------------------------
#创建四张表练习多表关联:
CREATE DATABASE school CHARSET utf8;
USE school;
CREATE TABLE student (
sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(20) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL COMMENT '年龄',
ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '性别'
) ENGINE=INNODB CHARSET=utf8;
CREATE TABLE course (
cno INT NOT NULL PRIMARY KEY COMMENT '课程编号',
cname VARCHAR(20) NOT NULL COMMENT '课程名字',
tno INT NOT NULL COMMENT '教师编号'
) ENGINE=INNODB CHARSET=utf8;
CREATE TABLE sc (
sno INT NOT NULL COMMENT '学号',
cno INT NOT NULL COMMENT '课程编号',
score INT NOT NULL DEFAULT 0 COMMENT '成绩'
) ENGINE=INNODB CHARSET=utf8;
CREATE TABLE teacher (
tno INT NOT NULL PRIMARY KEY COMMENT '教师编号',
tname VARCHAR(20) NOT NULL COMMENT '教师名字'
) ENGINE=INNODB CHARSET=utf8;
# 在数据库与数据表中插入模拟数据
INSERT INTO student(sno,sname,sage,ssex)
VALUES
(1,'zhang3',18,'m'),
(2,'zhang4',18,'m'),
(3,'li4',18,'m'),
(4,'wang5',19,'f'),
(5,'zh4',18,'m'),
(6,'zhao4',18,'m'),
(7,'ma6',19,'f'),
(8,'oldboy',20,'m'),
(9,'oldgirl',20,'f'),
(10,'oldp',25,'m');
INSERT INTO teacher(tno,tname)
VALUES
(101,'oldboy'),
(102,'xiaoQ'),
(103,'xiaoA'),
(104,'xiaoB');
INSERT INTO course(cno,cname,tno)
VALUES
(1001,'linux',101),
(1002,'python',102),
(1003,'mysql',103),
(1004,'go',105);
INSERT INTO sc(sno,cno,score)
VALUES
(1,1001,80),
(1,1002,59),
(2,1002,90),
(2,1003,100),
(3,1001,99),
(3,1003,40),
(4,1001,79),
(4,1002,61),
(4,1003,99),
(5,1003,40),
(6,1001,89),
(6,1003,77),
(7,1001,67),
(7,1003,82),
(8,1001,70),
(9,1003,80),
(10,1003,96);
SELECT * FROM student;
SELECT * FROM teacher;
SELECT * FROM course;
SELECT * FROM sc;
多表关联查询:两张表要有相同的列
1)内连接
select * from teacher,course where teacher.tno=course.tno;
select * from teacher join course on teacher.tno=course.tno;
2)外连接
左外连接:
利用左外连接时,会将left语句左边的表做驱动表(主表),右边的表作为被驱动表(子表)
在连接查询输出信息时,驱动表所有数据信息都会输出,被驱动只会将关联数据信息输出,不关联数据用null表示
select * from teacher left join course on teacher.tno=course.tno;
右外连接:
利用由外连接时,会将right语句右边的表做驱动表(主表),左边的表作为被驱动表(子表)
在连接查询输出信息时,驱动表所有数据信息都会输出,被驱动只会将关联数据信息输出,不关联数据用null表示
select * from teacher right join course on teacher.tno=course.tno;
连表练习操作:
01 统计zhang3,学习了几门课?
需要的表:student sc course
select student.sname,count(course.cname),group_concat(course.cname) from student
join sc
on student.sno=sc.sno
join course
on sc.cno=course.cno
where student.sname='zhang3';
+--------+---------------------+----------------------------+
| sname | count(course.cname) | group_concat(course.cname) |
+--------+---------------------+----------------------------+
| zhang3 | 2 | linux,python |
+--------+---------------------+----------------------------+
02 查询zhang3,学习的课程名称有哪些?
select student.sname,count(course.cname),group_concat(course.cname) from student
join sc
on student.sno=sc.sno
join course
on sc.cno=course.cno
where student.sname='zhang3';
+--------+---------------------+----------------------------+
| sname | count(course.cname) | group_concat(course.cname) |
+--------+---------------------+----------------------------+
| zhang3 | 2 | linux,python |
+--------+---------------------+----------------------------+
03 查询xiaoA老师教的学生名?
需要的表:teacher course sc student
select teacher.tno,teacher.tname,group_concat(student.sname) from teacher
join course
on teacher.tno=course.tno
join sc
on course.cno=sc.cno
join student
on sc.sno=student.sno
where teacher.tname='xiaoA'
group by teacher.tno;
xiaoA -- 老教师 -- 101
xiaoA -- 新教师 -- 201
04 查询xiaoA老师教课程的平均分数?
需要的表:teacher course sc
select teacher.tno,teacher.tname,course.cname,avg(sc.score) from teacher
join course
on teacher.tno=course.tno
join sc
on course.cno=sc.cno
where teacher.tname='xiaoA'
group by teacher.tno,course.cno;
xiaoA -- 老教师 -- 101
xiaoA -- 新教师 -- 201
xiaoA -- 老教师 -- mysql Linux
xiaoA -- 新教师 -- mysql Linux
05 每位老师所教课程的平均分,并按平均分排序?
select teacher.tno,teacher.tname,course.cname,avg(sc.score) from teacher
join course
on teacher.tno=course.tno
join sc
on course.cno=sc.cno
group by teacher.tno,course.cno
order by avg(sc.score);
06 查询xiaoA老师教的不及格的学生姓名?
select distinct student.sname from student s
join sc on s.sno=sc.sno
join course c on sc.cno=c.cno
join teacher t on c.tno=t.tno
where t.tname='xiaoA' and sc.score <60;
07 查询所有老师所教学生不及格的信息?
SELECT
t.tname AS 老师姓名, -- 教师姓名
s.sname AS 学生姓名, -- 学生姓名
c.cname AS 课程名称, -- 不及格的课程名
sc.score AS 分数 -- 不及格分数
FROM student s -- 学生表,别名s
JOIN sc ON s.sno = sc.sno -- 关联成绩表(学生号匹配)
JOIN course c ON sc.cno = c.cno -- 关联课程表(课程号匹配)
JOIN teacher t ON c.tno = t.tno -- 关联教师表(课程的授课教师号匹配)
WHERE sc.score < 60 -- 筛选不及格(60分及格)
ORDER BY t.tname ASC, s.sname ASC; -- 按老师姓名、学生姓名升序排序
+--------------+--------------+--------------+--------+
| 老师姓名 | 学生姓名 | 课程名称 | 分数 |
+--------------+--------------+--------------+--------+
| xiaoA | li4 | mysql | 40 |
| xiaoA | zh4 | mysql | 40 |
| xiaoQ | zhang3 | python | 59 |
+--------------+--------------+--------------+--------+
--------------------------------------------------------------
连表查询数据处理方法:
步骤一:需要掌握多张数据表的关联关系(绘制数据ER模型)
步骤二:根据查询需求,定位数据出现在哪些表中
步骤三:将定位数据表进行连表操作
步骤四:利用大表进行数据调取或统计分析(单表查询数据)
连表操作别名设置:
1)表别名设置
select a.tno,a.tname,b.cname,avg(c.score) from teacher as a
join course as b
on a.tno=b.tno
join sc as c
on b.cno=c.cno
group by a.tno,b.cno
order by avg(c.score);
select teacher.tno,teacher.tname,course.cname,avg(sc.score) from teacher
join course
on teacher.tno=course.tno
join sc
on course.cno=sc.cno
group by teacher.tno,course.cno
order by avg(sc.score);
2)列别名设置
select a.tno as 讲师编号,a.tname as 讲师名称,b.cname as 课程名称,avg(c.score) as 课程平均分 from teacher as a
join course as b
on a.tno=b.tno
join sc as c
on b.cno=c.cno
group by a.tno,b.cno
order by avg(c.score);
范围查询:
条件查询:
特殊条件组合查询:
聚合函数与多表联查:
聚合函数必须和 GROUP BY 配合使用(无分组时除外),而查询字段要么在 GROUP BY 里,要么被聚合函数包裹;如果只是 “全局统计”(比如统计整张表的总人数),可以不用 GROUP BY。
having 条件:HAVING 是 “分组后筛选结果”,必须写在 GROUP BY 后面,专门过滤聚合后的结果。
数据库服务引擎 索引 事务
引擎
存储引擎介绍
官方引擎介绍:https://dev.mysql.com/doc/refman/8.4/en/innodb-introduction.html
客户端:发起请求
1. 向服务端发送会话连接请求
2. 向服务端发送 SQL 语句信息
服务端:
1.连接器:处理客户端连接请求,建立会话
2.SQL层:
a. 语法校验、对象信息校验、权限识别
b. 自动选择执行方式(全表 / 索引,以 CPU、内存、IO 资源最优为目标)
c. 生成 SQL 最优执行计划
d. 按执行计划定位数据存储位置(查询 / 存储场景) 数据库 SQL 层
3.数据读写:与磁盘交互,完成数据的调取或存储
那谁来负责数据库的调取和存储? --数据库存储引擎存储引擎分类
MySQL 常见存储引擎类型、特点及应用:
1. Memory 存储引擎
核心逻辑:数据完全存储在内存中,依托内存的高速读写特性工作。
优势:读写速度极快,是所有引擎中性能最突出的类型之一。
缺点:不支持事务(数据安全性低)、不支持行级锁;服务器重启 / 断电后数据会直接丢失,无法持久化。
适用场景:追求读写速度,牺牲持久性 —— 比如缓存系统(临时存储热点数据)、会话数据存储、临时计算结果的中转存储。
2. MyISAM 存储引擎
核心定位:MySQL 5.5 版本之前的默认引擎,是早期 MySQL 的经典存储方案。
优势:高并发场景下读数据效率极高;支持全文索引、高速缓存,批量写入数据时性能也较好。
缺点:不支持事务(数据一致性难以保障)、不支持行级锁(并发写操作时性能受限);崩溃后数据恢复难度大,安全性较弱。
适用场景:追求读性能,牺牲安全性 —— 比如个人博客、新闻资讯网站(以内容展示为主,更新频率低)。
3. InnoDB 存储引擎
核心定位:MySQL 5.5 版本之后的默认引擎,是当前主流的生产环境选择。
优势:支持事务(满足 ACID 特性,保障数据一致性)、支持行级锁(提升并发写性能);自带聚簇索引(优化查询效率)、自动故障恢复功能,数据安全性强。
缺点:读性能略低于 MyISAM;因事务和锁机制,占用磁盘空间较大。
适用场景:追求安全与并发,平衡性能与可靠性 —— 比如金融系统(交易数据)、电商平台(订单 / 支付数据)、游戏后台(用户资产数据)。
存储引擎 操作与与设置
查看数据库可用的存储引擎
show engines;
查看某表的存储引擎信息
show create table 表名;
查看数据库默认存储引擎
select @@default_storage_engine;
创建表时指定存储引擎
create table 表名 (字段 数据类型 约束 索引) engine=存储引擎名称;
修改表的存储引擎
alter table 表名 engine=存储引擎名称
修改存储引擎:
方法1:永久修改数据库存储引擎
vim /etc/my.cnf
在[mysqld]模块添加:
default-storage-engine=MyISAM
重启:systemctl restart mysqld
方法2:临时修改数据库存储引擎
set global default_storage_engine='MyISAM';
独立表空间迁移(仅限 InnoDB 引擎)
数据库服务异常停止,无法再正常启动,且数据库没有做备份,没有搭建主从架构:
解决方法:
尝试使用整个数据目录进行数据恢复
利用表文件恢复数据(独立表空间迁移)
a.获取旧库数据表的结构信息:show create table 表名;
b.创建新数据库实例(新库3307)
c.创建原有数据库和数据表(需要知道旧库表结构)
create database world;
use world;
CREATE TABLE city (
ID int NOT NULL AUTO_INCREMENT,
Name char(35) NOT NULL DEFAULT '',
CountryCode char(3) NOT NULL DEFAULT '',
District char(20) NOT NULL DEFAULT '',
Population int NOT NULL DEFAULT '0',
PRIMARY KEY ID),
KEY CountryCode CountryCode)
) ENGINE=InnoDB;
d.表文件迁移
新库:alter table world.city discard tablespace;
含义: 执行discard是为了删除新库自动生成的空ibd文件,避免和后续从旧库复制来的ibd文件冲突,同时释放表空间的挂载状态,为导入旧文件做准备。
旧库数据目录拷贝:cp -a /data/3306/data/world/city.ibd /data/3307/data/world/
含义:将旧库的city.ibd(包含实际数据)复制到新库,是为了把旧库的表数据传递到新库。
新库: alter table world.city import tablespace;
含义:把复制过来的旧库city.ibd文件,重新挂载到新库已创建好的city表结构上,让新库的表结构与旧库的表数据关联起来,完成数据迁移。
旧库:
show create table city;
CREATE TABLE `city` (
`ID` int NOT NULL AUTO_INCREMENT,
`Name` char(35) NOT NULL DEFAULT '',
`CountryCode` char(3) NOT NULL DEFAULT '',
`District` char(20) NOT NULL DEFAULT '',
`Population` int NOT NULL DEFAULT '0',
PRIMARY KEY (`ID`),
KEY `CountryCode` (`CountryCode`)
) ENGINE=InnoDB;
新库:
mysql> create database world;
Query OK, 1 row affected (0.01 sec)
mysql> use world;
Database changed
mysql> CREATE TABLE `city` (
-> `ID` int NOT NULL AUTO_INCREMENT,
-> `Name` char(35) NOT NULL DEFAULT '',
-> `CountryCode` char(3) NOT NULL DEFAULT '',
-> `District` char(20) NOT NULL DEFAULT '',
-> `Population` int NOT NULL DEFAULT '0',
-> PRIMARY KEY (`ID`),
-> KEY `CountryCode` (`CountryCode`)
-> ) ENGINE=InnoDB;
Query OK, 0 rows affected (0.03 sec)
mysql> alter table world.city discard tablespace;
Query OK, 0 rows affected (0.02 sec)
旧库:
[root@kylin ~]# cp -a /data/3306/data/world/city.ibd /data/3307/data/world/
[root@kylin ~]# ll /data/3307/data/world/
总用量 592
-rw-r----- 1 mysql mysql 606208 12月 23 08:57 city.ibd
新库:
mysql> alter table world.city import tablespace;
Query OK, 0 rows affected, 1 warning (0.06 sec)
索引
1.1. 相关概念与详解
索引的核心作用是加速数据库的查询效率(减少IO消耗),还能避免数据重复(比如主键不能重复),相当于同时承担了 “数据校验” 的角色。
普通索引:最基础的索引,仅用于加速查询(无其他限制);
唯一索引:不仅加速查询,还强制字段值 “唯一不重复”(比如用户手机号不能重复);
主键索引:是 “特殊的唯一索引”,不仅唯一,还会作为表的 “主键标识”(每个表只能有一个),同时加速基于主键的查询;
联合索引:对多个字段组合建索引,适配 “多条件查询” 的场景(比如查 “姓名 + 性别” 时,用
(name, sex)联合索引加速)。
常用的索引类型模型:
索引树结构模型可视化网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
各索引的底层实现模型详解:(怎么存)
-- 全表扫描方式
select * from city where name='shanghai';
-- 二叉树索引应用
不用全表扫描数据
查询数据效率不均衡/按照顺序存储数据,会造成存储层次过高
-- BTREE
查询数据效率均衡/按照顺序存储数据,避免存储树形层次过高
将所有数据信息回存储到底层树形结构的叶节点中,树形结构支和根节点,只存储索引字段范围信息
-- B+TREE
增加了树形结构的横向指针功能,提高了数据库范围查询数据效率
B+tree数据查找过程?
设置页的最大数量
1.等值查询
加载索引信息,获取索引对应得数据信息
根节点--->支节点--->叶节点
2.范围查询
加载索引信息,获取索引对应得数据信息
根节点--->支节点--->叶节点--->指针
B-tree与B+tree区别?
B-tree:
进行索引构建时,根节点支节点页节点中,都会存储索引范围和数据信息
没有横向指针功能,无法实现快速查询范围数据
B+tree
进行索引构建时,根节点支节点只存储索引范围和指针信息,页节点中会存储索引范围和数据信息
mysql索引常见的底层数据结构?
B+TREE
分为三种结构:
根节点(只能有一个/只能有一层):存储索引字段范围信息,以及关联下层支节点的指针信息
支节点(可以有多个/可以有多层):存储索引字段范围信息,以及关联下层支节点/页节点的指针信息
页节点(可以有多个/只能有一层):存储索引字段信息,以及索引字段对应数据信息
利用B+Tree索引结构,如何实现真实索引数据信息?
聚簇索引应用:会将主键列作为索引列,并且会将主键列后的所有数据存储在底层数据页中
PS: 聚簇索引/主键索引必须在表中存在(手工创建 自动创建 隐式创建)
辅助索引应用:会将任意列作为索引列,并且会将索引列数据与关联的主键列数据存储到底层数据页中
PS:辅助索引应用必须手动创建,辅助索引应用需要加载聚簇索引(回表查询数据)
索引的功能 / 数据存储方式:(存什么、怎么关联)
聚簇索引:
聚簇索引的 B+树结构中,叶子节点直接存储整行数据(id=1, name='张三', age=20);
数据在磁盘上的物理存储顺序,就是聚簇索引的键(主键 id)的顺序(比如 id=1 的数据紧跟 id=2 的数据);
查询时:如果用主键查询(where id=1),直接遍历聚簇索引的 B+ 树,找到叶子节点就能拿到完整数据,无需额外操作。
辅助索引:
辅助索引的 B+ 树结构中,叶子节点只存储 “查询键(name)+ 聚簇索引键(id)”(比如 name='张三', id=1);
查询时:如果用辅助索引查询(where name='张三'),流程是:
先遍历 name 辅助索引的 B+ 树,找到叶子节点中的 id=1;
再用 id=1 遍历聚簇索引的 B+ 树,找到完整数据(这一步叫「回表」);
注意:如果查询的字段刚好在辅助索引中(比如 select name, id from student where name='张三'),无需回表(覆盖索引查询),效率和聚簇索引接近。
1.2. 索引应用
创建索引信息:
1.创建普通索引 -- MUL(索引列信息可以重复 可以为空值)
创建表时,将普通索引进行创建
CREATE TABLE student02 (
`sno` int NOT NULL COMMENT '学号',
`sname` varchar(20) NOT NULL COMMENT '姓名',
`sage` tinyint unsigned NOT NULL COMMENT '年龄',
`ssex` enum('f','m') NOT NULL DEFAULT 'm' COMMENT '性别',
index name(sname)
);
创建表后,将普通索引进行创建的两种方式
create index name on student(sname);
alter table student02 add index name(sname);
2.创建唯一索引 -- UNI(索引列信息不可以重复 可以为空值)
创建表时,将唯一索引进行创建
CREATE TABLE student04 (
`sno` int NOT NULL COMMENT '学号',
`sname` varchar(20) null COMMENT '姓名',
`sage` tinyint unsigned NOT NULL COMMENT '年龄',
`ssex` enum('f','m') NOT NULL DEFAULT 'm' COMMENT '性别',
UNIQUE index name(sname)
);
创建表后,将唯一索引进行创建的两种方式
create unique index name on student04(sname) ;
ALTER TABLE student04 ADD UNIQUE name(sname);
3.创建主键索引 -- PRI(索引列信息不可以重复 不可以为空值)
创建表时,将主键索引进行创建
CREATE TABLE student05 (
`sno` int NOT NULL COMMENT '学号',
`sname` varchar(20) not null COMMENT '姓名',
`sage` tinyint unsigned NOT NULL COMMENT '年龄',
`ssex` enum('f','m') NOT NULL DEFAULT 'm' COMMENT '性别',
primary key (sname)
);
创建表后,将主键索引进行创建
ALTER TABLE student05 ADD PRIMARY KEY (sname);
4.创建联合索引
创建表时,将联合索引进行创建
CREATE TABLE student05 (
`sno` int NOT NULL COMMENT '学号',
`sname` varchar(20) not null COMMENT '姓名',
`sage` tinyint unsigned NOT NULL COMMENT '年龄',
`ssex` enum('f','m') NOT NULL DEFAULT 'm' COMMENT '性别',
index name_ssex(sname,ssex)
);
查看联合索引:show index from student05\G
创建表后,联合索引的两种创建方式
直接创建:create index name_ssex on student05(sname,ssex);
ALTER表添加:alter table student05 add index name_ssex (sname,ssex);
联合索引要遵循最左原则:
规则1:查询时必须应用最左列的索引,否则联合索引可能失效。
规则2:创建联合索引时,应将重复值较少的列作为最左列(可提升索引效率)。
-----------------------------------------------------------------------------
查看索引信息(确认索引是否创建成功/创建索引是否合理)
desc 表名 -- 在获取表结构同时,可以利用key字段,查看表中索引设置情况
show index from 表名 -- 查看表中索引设置情况
删除索引信息(占用磁盘空间/影响查询效率)
删除主键索引:
alter table 表名 drop primary key;
或
drop index primary on 数据表名;
删除其它索引:
alter table 表名 drop index 索引名;
或
drop index 索引名 on 数据表名; 索引信息解读(show index from student05\G)
步骤一:创建压测数据表(大表)
mysql -uroot -S /tmp/mysql3306.sock <./t100w_oldboy.sql
步骤二:先将测试数据表中索引清除
alter table 表名 drop primary key;
alter table 表名 drop index 索引名;
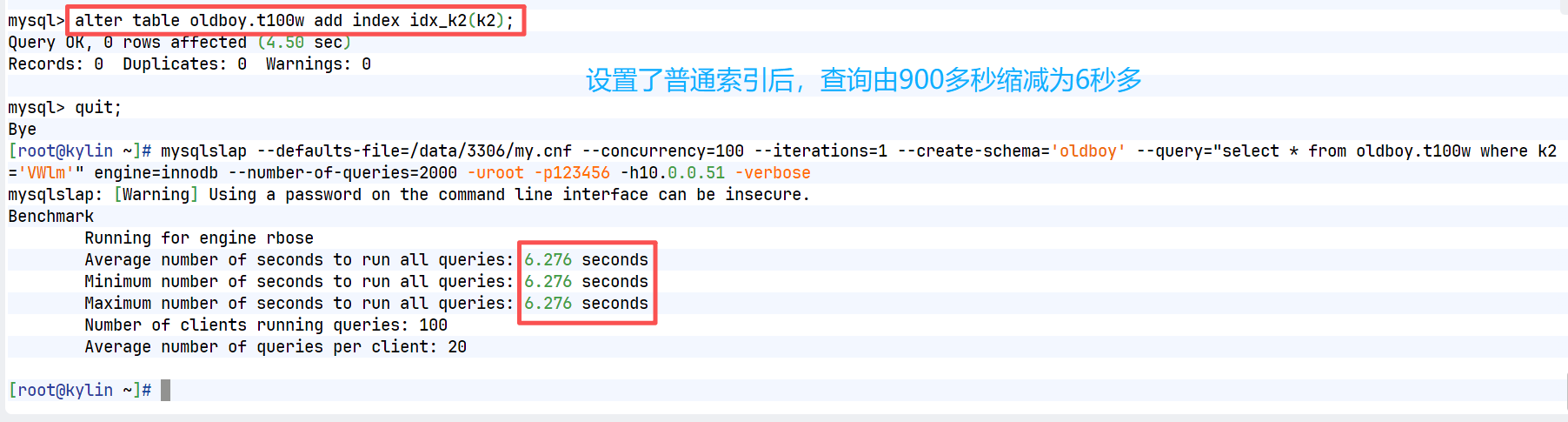
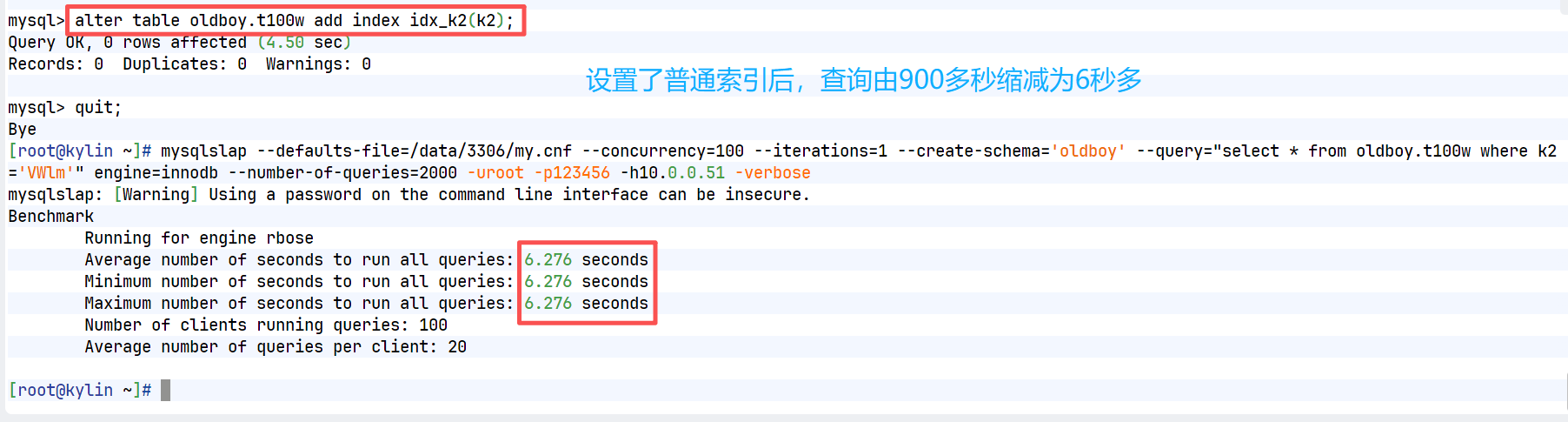
步骤三:执行压测命令,进行查询操作
mysqlslap --defaults-file=/data/3306/my.cnf --concurrency=100 --iterations=1 --create-schema='oldboy' --query="select * from oldboy.t100w where k2='VWlm'" engine=innodb --number-of-queries=2000 -uroot -p123456 -h10.0.0.51 -verbose
--concurrency=100 -- 模拟并发访问数量测试
--iterations=1
--create-schema='oldboy' -- 指定访问哪个数据库中数据
--query="select * from oldboy.t100w where k2='VWlm'" -- 模拟向数据库服务端发送什么请求
--number-of-queries=2000 -- 向服务端发送请求处理次数
步骤四:添加索引信息
alter table oldboy.t100w add index idx_k2(k2);
步骤五:重新进行压力测试
mysqlslap --defaults-file=/data/3306/my.cnf --concurrency=100 --iterations=1 --create-schema='oldboy' --query="select * from oldboy.t100w where k2='VWlm'" engine=innodb --number-of-queries=2000 -uroot -p123456 -h10.0.0.51 -verbose

1.3. 索引标识

事务
事务ACID相关知识官方说明:https://dev.mysql.com/doc/refman/8.0/en/mysql-acid.html
什么是事务:事务是数据库里一组操作的打包集合:这组操作要么 “全成功执行”,要么 “全回滚到最初状态”,以此保证数据操作的安全、一致(比如银行转账,扣钱和加钱必须同时成 / 同时不成)。
事务的四大特性常被称为 ACID:
原子性:事务是 “最小操作单元”,要么所有操作全执行,要么全回滚(比如转账的 “扣钱 + 加钱” 必须同成同败)。
一致性:事务执行前后,数据的业务规则保持一致(比如转账前后,双方总金额不变)。
隔离性:多个事务同时运行时,互相隔离、互不干扰(不会看到对方的 “中间未完成状态”)。
持久性:事务成功提交后,数据永久保存(哪怕数据库故障重启,结果也不会丢失)。
1.1. 事务提交方式
查看是否开启自动提交
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
修改自动提交
#临时关闭事务自动提交功能
mysql> set global autocommit=0;
-- 配置调整后,重新登录mysql数据库生效
#永久关闭事务自动提交功能
[root@xiaoQ-01 ~]# vim /etc/my.cnf
[mysqld]
autocommit=0
-- 配置调整后,重新启动mysql数据库生效
事务提交方式:
方式一:自动应用事务
autocommit=1 开启事务自动提交
优点:自动保存功能,可以保证数据操作安全性/持久性
缺点:所有语句操作过程,不具备原子性
autocommit=0 关闭事务自动提交
优点:所有语句操作过程,具备原子性
缺点:异常断开后,所有操作将不自动保存,操作丢失
方式二:手动应用事务,隐式提交方式
开始记录事务:begin;
操作:DML1; DML2; DDL1; COMMIT; DML3;
撤销:rollback;
提交:COMMIT;
1.2. 隐式自动提交
有几种情况,即使没有 commit,也自动触发隐式提交
隐式自动回滚情况分析:
情况一:在事务操作过程中,会话窗口自动关闭了,会进行隐式自动回滚;
情况二:在事务操作过程中,数据库服务被停止了,会进行隐式自动回滚;
情况三:在事务操作过程中,出现事务冲突死锁了,会进行隐式自动回滚;
1.3. 事务所需的日志文件
回滚文件 undo 实现事务事件信息回滚撤销功能 --保证事务的原子性
重做文件 redo 实现事务事件信息重做操作功能 --保证事务的持久性
双写文件 .dblwr 实现将数据页信息进行保存文件 --保证事务的一致性
1.4. 事务隔离级别(保证事务 I 特性)
事务隔离级别官方链接:https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html
并发事务的 3 个典型问题:
脏读:读到其他事务未提交的临时数据(数据可能被回滚,是 “无效脏数据”);【去银行查流水】
不可重复读:同一事务内多次读取同一数据,每次进行统计分析的数据结果不一致(被其他事务修改并提交);【公司财务统计营业额】
幻读:同一事务内多次执行同一查询,结果集行数不一致(被其他事务插入 / 删除并提交)。【分公司员工工作 25 年没被评级】
死锁:两个事务交叉请求对方已持有的锁,就会满足 “死锁四大条件”(互斥、持有并等待、不可剥夺、循环等待),触发死锁。
类型一:RU(READ-UNCOMMITTED 表示读未提交)
可以读取到事务未提交的数据,隔离性差
会出现脏读(当前内存读),不可重复读,幻读问题;
类型二:RC(READ-COMMITTED 表示读已提交)
可以读取到事务已提交的数据,隔离性一般,不会出现脏读问题
但是会出现不可重复读,幻读问题;
类型三:RR(REPEATABLE-READ 表示可重复读)
可以防止脏读(当前内存读),防止不可重复读问题,防止会出现的幻读问题,但是并发能力较差;
会使用next lock锁进制,来防止幻读问题,但是引入锁进制后,锁的代价会比较高,比较耗费CPU资源,占用系统性能;
类型四:SR(SERIALIZABLE 可串行化)
隔离性比较高,可以实现串行化读取数据,但是事务的并发度就没有了;
这是事务的最高级别,在每条读的数据上,加上锁,使之不可能相互冲突
死锁概率比其他级别更高。
create database oldboy;
use oldboy
create table t1 (
id int not null primary key auto_increment,
a int not null,
b varchar(20) not null,
c varchar(20) not null
) charset=utf8mb4 engine=innodb;
begin;
insert into t1(a,b,c)
values
(5,'a','aa'),
(7,'c','ab'),
(10,'d','ae'),
(13,'g','ag'),
(14,'h','at'),
(16,'i','au'),
(20,'j','av'),
(22,'k','aw'),
(25,'l','ax'),
(27,'o','ay'),
(31,'p','az'),
(50,'x','aze'),
(60,'y','azb');
commit;
-----------------------------------------------------------
# 查看事务隔离级别(默认RR)
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| REPEATABLE-READ |
+-------------------------+
1 row in set (0.00 sec)
# 设置事务隔离级别
set global transaction_isolation='READ-UNCOMMITTED';
set global transaction_isolation='READ-COMMITTED';
set global transaction_isolation='REPEATABLE-READ';
场景01 READ-UNCOMMITTED(示例读脏数据)
事务 A:set global transaction_isolation='READ-UNCOMMITTED';(设置隔离级别);
事务 A:update t1 set a=a+10 where id=3;(执行后未 COMMIT)
事务 B:select * from t1; 读到 a=20(这是 “脏数据”)
事务 A:ROLLBACK;(回滚修改);
事务 B 再读:a变回原来的 10,相当于读了 “无效数据”;
场景02 READ-COMMITTED(示例不可重复读)
事务 A:SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;(设置隔离级别);
事务 A:SELECT a FROM t1 WHERE id=7; → 读到 a=20(初始值);
事务 B:UPDATE t1 SET a=a+5 WHERE id=7; COMMIT;(提交修改,id=7 的 a 变为 25);
事务 A:再次执行 SELECT a FROM t1 WHERE id=7; → 读到 a=25(同一事务内两次读结果不同,即不可重复读);
场景03 REPEATABLE READ(示例可重复读 + 幻读解决)
子场景 1:可重复读体现
事务 A:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;(设置隔离级别);
事务 A:SELECT a FROM t1 WHERE id=11; → 读到 a=31(初始值);
事务 B:UPDATE t1 SET a=a+10 WHERE id=11; COMMIT;(提交修改,id=11 的 a 变为 41);
事务 A:再次执行 SELECT a FROM t1 WHERE id=11; → 仍读到 a=31(同一事务内重复读结果一致);
子场景 2:幻读解决(InnoDB 特性)
事务 A:SELECT COUNT(*) FROM t1 WHERE a>25; → 查到 4 条(id=10/11/12/13,a 分别为 27/31/50/60);
事务 B:INSERT INTO t1(a,b,c) VALUES (30,'z','azc'); COMMIT;(新增 a=30 的记录,满足 a>25);
事务 A:再次执行 SELECT COUNT(*) FROM t1 WHERE a>25; → 仍查到 4 条(InnoDB 通过 MVCC 避免幻读);
场景04 SERIALIZABLE(示例串行执行与死锁)
事务 A:SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;(设置隔离级别);
事务 A:BEGIN; SELECT * FROM t1 WHERE a>50; → 查到 1 条(id=13,a=60),执行后未 COMMIT(对符合条件的记录加锁);
事务 B:尝试执行 INSERT INTO t1(a,b,c) VALUES (55,'m','azd'); → 被阻塞(无法插入满足 a>50 的记录);
事务 A:COMMIT;(提交事务,释放锁);
事务 B:阻塞解除,INSERT 语句执行成功;
死锁触发过程:
事务 A:BEGIN; → 开启事务事务 A:UPDATE t1 SET b='aa_new' WHERE id=3; → 成功执行,持有 id=3 的行锁(未提交,不释放锁);
事务 B:BEGIN; → 开启事务事务 B:UPDATE t1 SET b='c_new' WHERE id=7; → 成功执行,持有 id=7 的行锁(未提交,不释放锁);
事务 B:UPDATE t1 SET b='aa_new2' WHERE id=3; → 尝试获取 id=3 的锁,但被事务 A 持有,事务 B 进入阻塞等待;
事务 A:UPDATE t1 SET b='c_new2' WHERE id=7; → 尝试获取 id=7 的锁,但被事务 B 持有,事务 A 进入阻塞等待;
此时形成 “循环等待链”:事务 A 持有 id=3 的锁→等 id=7 的锁;事务 B 持有 id=7 的锁→等 id=3 的锁 → 死锁触发。
最终结果
MySQL 内置的死锁检测机制会立即发现这个循环等待,终止其中一个事务(通常是后发起锁请求的那个),抛出错误:
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
被终止的事务会回滚,另一个事务则可以继续执行。
数据库日志 备份 恢复
1. 数据库日志都有什么
数据库中日志查询:show variables like '%log%';
2. 数据库日志配置(日志的开启与存放位置)
2.1. 通用日志
永久生效:修改配置文件(my.cnf)
#设置通用日志功能是否开启或关闭
general_log=on
#定义通用日志存储路径以及名称信息
general_log_file=/data/3306/logs/general.log
临时生效:全局变量临时激活(不重启,重启失效)
#临时开启通用日志(立即生效,重启MySQL后恢复默认)
mysql > set global general_log=1;
#验证是否开启(返回VALUE=ON/YES表示已激活)
mysql > show variables like 'general_log';2.2. 错误日志
# 修改日志存储路径(永久配置):
[root@db01 ~]# vim /etc/my.cnf
log_error=/data/3306/logs/error.log #指定错误日志存储路径和文件名称
配置文件编写完毕后,需要重启数据库服务生效2.3. 二进制日志
#查看系统binlog功能配置参数状态
mysql> show variables like '%log_bin%';
永久生效:
#开启数据库binlog日志记录功能
[root@db01 ~]# vim /etc/my.cnf
server_id=2
log_bin=/data/3306/logs/binlog #指定二进制日志存储路径和文件名称
配置文件编写完毕后,需要重启数据库服务生效
临时生效:
mysql> set session sql_log_bin=ON;
#读取binlog日志方法
mysqlbinlog binlog.000001
----------------------------------------------------------------------------------------
binlog日志配置扩展:
# 参数一:sync_binlog 表示刷新日志到磁盘策略
sync_binlog:日志信息记录生成后(内存中生成)保存到磁盘的时机,直接影响 binlog 的安全性和 IO 性能。
此参数信息是有三种方式进行配置的:官方资料链接:https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html
-- 参数信息配置0:由操作系统缓存自己决定,什么时候刷新日志到磁盘中;(测试环境 / 对性能要求极高、对数据安全性要求低的场景)
-- 参数信息配置1:每次事务提交,立即刷新日志到磁盘中;(此方式配置更安全,生产环境(主从同步双一标准),数据零丢失优先)
-- 参数信息配置N(N>1):每累计 N 个事务提交时,才刷一次 binlog 到磁盘;(可以有效减少IO性能损耗,对性能要求高、可接受少量数据丢失的场景(如 N=100))
「双 1 配置」:主从同步的最高安全标准
第一个 1:sync_binlog = 1(binlog 刷盘策略)
第二个 1:innodb_flush_log_at_trx_commit = 1(InnoDB 事务日志刷盘策略)
临时生效(重启 MySQL 后失效)
SET GLOBAL sync_binlog = 1;
select @@sync_binlog;
+---------------------+
| @@sync_binlog |
+---------------------+
| 1 |
+---------------------+
1 row in set (0.00 sec)
永久生效
vim /etc/my.cnf
[mysqld]
sync_binlog = 1
# 参数二:binlog_format 定义binlog日志的格式信息
查看binlog日志格式
mysql> select @@binlog_format;
+------------------------+
| @@binlog_format |
+------------------------+
| ROW |
+------------------------+
1 row in set (0.00 sec)
有三种模式:ROW、STATEMENT、MIXED
-- 参数信息配置 row(RBR):行格式记录binlog(默认模式)
-- 参数信息配置 statement(SBR):语句格式记录binlog;
-- 参数信息配置 mixed(MBR):混合格式记录binlog
临时生效:
SET GLOBAL binlog_format = 'ROW';
SET GLOBAL binlog_format = 'STATEMENT';
SET GLOBAL binlog_format = 'MIXED';
永久生效
vim /etc/my.cnf
[mysqld]
binlog_format = ROW
-------------------------------------------------------------------------------------------
关键注意事项(避坑重点)
● 主从同步风险:主库会话关闭 sql_log_bin 后,该会话的操作不会写入 binlog → 从库无法同步这些操作,导致主从数据不一致(仅允许临时、可控场景使用);
● 权限限制:MySQL 8.0 后,普通用户无权限修改 sql_log_bin,需赋予 REPLICATION_ADMIN 权限:
● grant REPLICATION_ADMIN on *.* to '用户名'@'主机';
● 全局修改的局限性:set global sql_log_bin=OFF 仅对修改后新建的连接生效,已有连接仍保持原有状态;
● 无法在事务中修改:必须在事务外执行 set session sql_log_bin,否则报错(因为 binlog 是事务级的,中途开关会破坏一致性);
● 与 log_bin 的关系:log_bin 是全局开启 / 关闭 binlog(实例级),sql_log_bin 是在 log_bin 开启的前提下,细粒度控制某会话 / 全局是否写入(开关级)—— 如果 log_bin=OFF(实例级关闭 binlog),则 sql_log_bin 无论取值如何都无效。查看方式一:确认数据库binlog日志数量
#获取数据库服务运行过程中,使用的binlog日志的情况
mysql> show binary logs;
+------------------+-------------+--------------+
| Log_name | File_size | Encrypted |
+------------------+-------------+--------------+
| binlog.000001 | 156 | No |
+------------------+-------------+--------------+
mysql> flush logs;
#可以执行flush刷新命令,从而生成新的binlog日志文件,类似于实现了日志切割功能;
mysql> show binary logs;
+------------------+-------------+--------------+
| Log_name | File_size | Encrypted |
+------------------+-------------+--------------+
| binlog.000001 | 200 | No |
| binlog.000002 | 156 | No |
+------------------+-------------+--------------+
2 rows in set (0.00 sec)
查看方式二:当前数据库binlog日志状态
#查看获取当前使用的binlog日志情况,以及产生的日志量字节大小;
mysql> show master status;
+------------------+------------+------------------+-----------------------+-------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+------------+------------------+-----------------------+-------------------------+
| binlog.000002 | 362 | | | |
+------------------+------------+------------------+-----------------------+-------------------------+
1 row in set (0.00 sec)
Binlog_Do_DB -- 二进制日志做记录的白名单设置 binlog_do_db=xiaoA
Binlog_Ignore_DB -- 二进制日志做记录的黑名单设置 binlog_ignore_db=xiaoB
Executed_Gtid_Set -- 全局事务编号功能没开启 数据库运行后,都完成了多少事务
查看方式三:查看数据库binlog日志信息(以表格呈现)
mysql> show binlog events in 'binlog.000002';
-- binlog日志信息是以事件方式进行记录的,所以日志查看过程是查看事件信息
-- 一般binlog日志的前两行,表示日志格式头信息(日志简单的描述信息)
-- 一般binlog日志中的query信息,就是对数据库的操作语句,其中包含了创建数据库的语句;
具体binlog事件记录信息分析:
Log_name 表示指定查看的binlog日志文件名称信息
Pos 表示binlog日志事件开始的位置点,用于截取二进制日志信息标识
End_log_pos 表示binlog日志事件结束的位置点,用于截取二进制日志信息标识
Info 表示binlog中具体的事件内容信息
查看方式四:直接查看binlog日志文件信息
[root@db01 ~]# mysqlbinlog --base64-output=decode-rows -vvv /data/3306/data/binlog.000003
-- 以上添加的参数信息,表示将DML的ROW格式语句信息,进行格式化处理输出;
# at 739
#221121 13:17:45 server id 1 end_log_pos 779 CRC32 0xb468b459 Write_rows: table id 101 flags: STMT_END_F
### INSERT INTO `bindb`.`t1`
-- 利用DML语句做的插入语句信息就显示出来了
### SET
### @1=1 /* INT meta=0 nullable=1 is_null=0 */
-- 以上日志记录的信息,可以用命令实现,如下:
mysql > insert into t1 set id=1;
等价于
mysql > insert into t1 values(1);2.3.1. 日志切割:(控制 binlog 文件的最大大小,自动切割)
# 方法一:手动切隔
mysql> flush logs;
或
[root@db01~ ]# mysqladmin -uroot -p123456 flush-logs
或
重启数据库
[root@db01 ~ ]# /etc/init.d/mysqld restart
# 方式二:自动切隔
mysql> select @@max_binlog_size;
+--------------------------+
| @@max_binlog_size |
+--------------------------+
| 1073741824 |
+--------------------------+
-- 配置binlog日志最大数据存储量,默认大小为1G,到达最大日志存储量也会进行自动切割;
临时修改生效:
SET GLOBAL max_binlog_size = 512M;
永久生效(生产环境推荐,需改配置文件 + 重启):
vim /etc/my.cnf
[mysqld]
max_binlog_size = 512M
注意事项:
不建议将 max_binlog_size 设置过小(如 <100MB):会导致 binlog 文件数量暴增,造成 inode 不足,增加管理成本;也不建议过大(如> 4GB):会导致 binlog 日志解析、恢复耗时变长。
生产环境常用值:512M ~ 2G(根据业务量调整,推荐 1G)。
binlog 切割仅由 max_binlog_size 和 “手动切换”(FLUSH LOGS;)触发,与时间无关;如果需要按时间切割 binlog,需结合定时任务执行 FLUSH LOGS;(比如每天凌晨执行)。
2.3.2. 日志清理
方式一:手动清理
mysql> purge binary logs to 'mysql-bin.010'
-- 删除到指定日志文件前结束
mysql> PURGE BINARY LOGS BEFORE '2025-12-26 11:20:00';
-- 可以基于日志时间点信息进行日志清理
方式二:自动清理
mysql> show variables like '%expire%';
+-------------------------------------+-----------+
| Variable_name | Value |
+-------------------------------------+-----------+
| binlog_expire_logs_seconds | 2592000 |
| expire_logs_days | 0 |
+-------------------------------------+-----------+
3 rows in set (0.00 sec)
-- 在最新数据库8.0中,可以以秒为单位进行日志信息清理,默认是30天进行日志清理,或者也可以以天为单位进行清理;
-- 在最先数据库8.0前,主要是以天为单位进行清理,但默认清理功能并未激活;
-- 在企业实战环境中,建议过期时间最少保留一轮全备周期以上,有条件最好是保留两轮+1;
2.3.3. 日志远程备份
步骤一:克隆创建新的日志备份服务器
单独指定一台存储服务器(磁盘存储空间充足)
步骤二:在新的日志备份服务器中创建存储目录和安装数据库程序
mkdir -p /backup/10.0.0.51/
安装数据库过程省略....
步骤三:实现日志远程备份功能
cd /backup/10.0.0.51/
mysqlbinlog -R --host=10.0.0.51 --user=root --password=123456 --raw --stop-never binlog.000012 &
-R 实现远程连接数据库服务
--raw 读取数据库服务binlog日志信息(实时读取)
--stop-never 实现远程备份守护进程功能
binlog.000001 从哪个binlog日志开始同步
2.3.4. 日志信息截取-实现恢复
指定起始和结束位置
可以使用 --start-position 和 --stop-position 参数来指定你想要查看的二进制日志的起始和结束位置事件
mysqlbinlog --start-position=234 --stop-position=901 binlog.000015
指定起始和结束时间
可以使用--start-datetime 和 --stop-datetime 参数来指定你想要查看的二进制日志的起始和结束时间事件信息
mysqlbinlog --start-datetime="2023-01-01 00:00:00" --stop-datetime="2023-01-02 00:00:00" binlog.000001
过滤特定的对象数据
可以使用 --to-last-log 参数来查看从指定文件开始到最后一个日志文件的全部内容,或结合使用 --database 来过滤特定数据库的事件。
# 从binlog日志中,过滤有关特定数据库的所有事务事件信息
mysqlbinlog -R --base64-output=decode-rows -vvv --database=xiaoB --to-last-log binlog.000016
2.3.5. 二进制日志信息数据闪回功能
针对误操作---闪回工具+binlog
步骤一:下载闪回工具包
ll /opt/binlog2sql-master.zip
-rw-r--r-- 1 root root 15030 10月 10 2022 /opt/binlog2sql-master.zip
步骤二:安装闪回工具包
[root@oldboy-db01 opt]# cd binlog2sql-master/
[root@oldboy-db01 binlog2sql-master]# ll
总用量 44
-rwxr-xr-x 1 root root 9155 10月 29 2019
binlog2sql.py
-- 加压软件程序压缩包,会生成程序目录,在程序目录中可以有python脚本信息
步骤三:部署python脚本运行环境
yum install -y python3 python3-pip
pip3 install -r requirements.txt
执行闪回操作:
python3 binlog2sql.py -h10.0.0.51 -P3306 -uroot -p123456 -d school -t student --sql-type=update --start-file='binlog.00009' -B
--start-file='binlog.00009' 这里指定的是当前操作的 binlog
2.4. 慢查询日志
#查看是否激活启动慢日志记录功能(1 代表激活)
mysql> select @@slow_query_log;
#慢日志文件保存的路径信息
select @@slow_query_log_file;
#查看设置时间(默认是大于10s执行的语句,就会记录为慢查询语句)
select @@long_query_time;
#查询是否记录没有使用索引的语句信息
select @@log_queries_not_using_indexes;
#激活日志:
slow_query_log=1
-- 是否开启慢查询日志功能 on/1 表示创建慢查询日志 off/0 表示禁用慢查询日志
set global slow_query_log=1;
-- 定义慢查询日志存储路径以及日志名称
set global long_query_time=0.01;
-- 定义超过多长时间的语句被定义为慢查询语句
set global log_queries_not_using_indexes=1;
-- 定义某些查询语句没有应用索引,会将语句记录慢查询日志3. 数据库备份与恢复
备份一般为从库备份
3.1. 方式一:逻辑备份恢复【数据量少的情况,可以应用逻辑备份( <50G )】
1. 全备
本地:mysqldump -uroot -p -S /tmp/mysql3306.sock -A >/backup/all.sql
远程:mysqldump -uroot -p -h 数据库地址 -P 端口 -A >/backup/all.sql
恢复:mysql -uroot -p </backup/all.sql
2. 分库备份:
mysqldump -uroot -p -S /tmp/mysql3306.sock -B 数据库1 数据库2 >/backup/xxx库.sql
恢复:mysql -uroot -p </backup/xxx.sql
3. 分表备份:
mysqldump -uroot -p -S /tmp/mysql3306.sock 库名 表名1 表名2 /backup/xxx表.sql
恢复:mysql -uroot -p 库名 </backup/xxx 表.sql
数据库数据备份进阶方式一:利用命令参数 --single-transaction
--single-transaction 在数据库进行数据库时,开启瞬时快照机制(MVCC),可以实现数据库备份期间正常做数据处理
数据库数据备份进阶方式二:利用命令参数 --source-data=2
--source-data=2 在数据库备份后,记录备份结束后的事务位置点信息,它主要作用是实现主从之前快速同步数据
数据库数据备份进阶方式三:利用命令参数 --routines --triggers
--routines --triggers 在数据库备份数据时,将事件存储过程和触发器信息一并做备份
3.2. 方式二:物理备份恢复【>50G 时,最好应用物理备份】
#备份
步骤一:需要先确认业务停止访问数据库
前端开发人员 -- 停止数据库数据信息变化
后端数据库人员 -- 停止数据库数据信息变化
步骤二:停止数据库服务运行
systemctl stop mysqld3306
步骤三:进行数据库底层数据信息备份
mkdir -p /backup/data
cp -a /data/3306/data/* /backup/data/
步骤四:运行启动数据库服务,恢复正常业务
systemctl start mysqld3306
#恢复
步骤一:需要先确认业务停止访问数据库
前端开发人员 -- 停止数据库数据信息变化
后端数据库人员 -- 停止数据库数据信息变化
步骤二:停止数据库服务运行
systemctl stop mysqld3306
步骤三:删除清理原有数据库中数据
rm -rf /data/3306/data/*
步骤四:将备份数据进行迁移恢复
cp -a /backup/data/* /data/3306/data/
步骤五:重新启动数据库服务,做数据检查
systemctl start mysqld3306
步骤六:恢复数据库正常业务运行
再次检查是否恢复xbk 热备工具:https://www.percona.com/downloads/
步骤一:下载工具
步骤二:安装软件包
#解压到指定目录
[root@kylin ~]# tar xf percona-xtrabackup-8.0.35-34-Linux-x86_64.glibc2.28.tar.gz -C /usr/local/
[root@kylin ~]# cd /usr/local/
[root@kylin local]# ll
总用量 0
drwxr-xr-x 8 root root 101 8月 7 18:40 percona-xtrabackup-8.0.35-34-Linux-x86_64.glibc2.28
#创建软链接
[root@kylin local]# ln -s percona-xtrabackup-8.0.35-34-Linux-x86_64.glibc2.28/ xbk
[root@kylin local]# ll
总用量 0
drwxr-xr-x 8 root root 101 8月 7 18:40 percona-xtrabackup-8.0.35-34-Linux-x86_64.glibc2.28
lrwxrwxrwx 1 root root 52 12月 29 10:35 xbk -> percona-xtrabackup-8.0.35-34-Linux-x86_64.glibc2.28/
#配置环境变量
[root@kylin local]# vim /etc/profile
export PATH="$PATH:/usr/local/mysql/bin:/usr/local/xbk/bin"
[root@kylin local]# source /etc/profile
#查看版本,测试工具是否安装成功
[root@kylin local]# xtrabackup -version
xtrabackup version 8.0.35-34 based on MySQL server 8.0.35 Linux (x86_64) (revision id: c8a25ff9)
--------------------------------------------------------------------------------------------
--全量备份
#创建备份目录
[root@kylin local]# mkdir -p /backup/mysql-bak
#找到你数据库的配置文件
[root@kylin local]# ll /data/3306/my.cnf
-rw-r--r-- 1 mysql mysql 266 12月 25 19:42 /data/3306/my.cnf
#查看数据库用户的连接权限地址
mysql> SELECT user, host, plugin FROM mysql.user WHERE user = 'root';
+------+-----------+-----------------------+
| user | host | plugin |
+------+-----------+-----------------------+
| root | 10.0.0.% | caching_sha2_password |
| root | localhost | caching_sha2_password |
+------+-----------+-----------------------+
2 rows in set (0.00 sec)
#安装依赖:perl-DBD-MySQL 是 Perl 语言的 MySQL 数据库驱动模块。作用:Perl 脚本(xtrabackup 底层大量依赖 Perl 开发)通过这个模块实现与 MySQL 服务器的通信(比如连接认证、读取数据库元信息、获取 InnoDB LSN 号等),是 Perl 程序操作 MySQL 的 “桥梁”。
yum install -y perl-DBD-MySQL
apt install libdbd-mysql-perl
#备份
xtrabackup --defaults-file=/data/3306/my.cnf --host=10.0.0.51 --user=root --password=123456 --port=3306 --backup --target-dir=/backup/mysql-bak
#恢复
#1.恢复需要先停止数据库服务
mysql>shutdown
或者
systemctl stop mysqld3306.service
#2.假设数据目录损坏
\rm -rf /data/3306/data/* /data/3306/logs/*
#3.先将原有数据库中内存数据恢复
xtrabackup --prepare --target-dir=/backup/mysql-bak
#4.再将原有数据库中磁盘数据迁移恢复
xtrabackup --defaults-file=/data/3306/my.cnf --copy-back --target-dir=/backup/mysql-bak
#5.恢复属主权限
chown -R mysql.mysql /data/3306/
#6.重启检查
systemctl start mysqld3306
--增量备份(只备份有变化的部分)
#创建全量空目录
mkdir -p /backup/mysql-bak
[root@kylin ~]# ll /backup/mysql-bak/
总用量 0
#创建增量空目录
mkdir -p /backup/mysql-inc-12mon
#安装依赖
yum install -y perl-DBD-MySQL
apt install libdbd-mysql-perl
#备份全量
xtrabackup --defaults-file=/data/3306/my.cnf --host=10.0.0.51 --user=root --password=123456 --port=3306 --backup --parallel=4 --target-dir=/backup/mysql-bak
#模拟创建增量数据
create database test01;
use test01;
create table t1(id int);
insert into t1 values(1),(2),(3);
commit;
#备份增量
xtrabackup --defaults-file=/data/3306/my.cnf --host=10.0.0.51 --port=3306 --user=root --password=123456 --backup --parallel=4 --target-dir=/backup/mysql-inc-12mon --incremental-basedir=/backup/mysql-bak
#增量恢复
mysql>shutdown
或
systemctl stop mysqld3306.service
#模拟数据目录损坏
\rm -rf /data/3306/data/* /data/3306/logs/*
#将全量数据和增量数据信息做合并
xtrabackup --prepare --apply-log-only --target-dir=/backup/mysql-bak
xtrabackup --prepare --apply-log-only --target-dir=/backup/mysql-bak --incremental-dir=/backup/mysql-inc-12mon
#参数说明:
--apply-log-only
简单说明:利用此参数可以实现全量+增量恢复数据的一致性
官方解释:禁止增量恢复数据时,在undo信息,只在恢复数据时在redo信息
#将合并后的数据,对应内存区域数据还原恢复
xtrabackup --prepare --target-dir=/backup/mysql-bak
#将合并后的数据,对应磁盘区域数据还原恢复
xtrabackup --defaults-file=/data/3306/my.cnf --copy-back --target-dir=/backup/mysql-bak
#修复属主权限
chown -R mysql:mysql /data/3306/data/
chown -R mysql:mysql /data/3306/logs/
[root@kylin backup]# systemctl start mysqld3306.service
[root@kylin backup]# systemctl status mysqld3306.service
● mysqld3306.service - MySQL Server
Loaded: loaded (/etc/systemd/system/mysqld3306.service; disabled; vendor preset: disabled)
Active: active (running) since Mon 2025-12-29 18:22:54 CST; 4s ago
Docs: man:mysqld(8)
http://dev.mysql.com/doc/refman/en/using-systemd.html
Main PID: 1108951 (mysqld)
Tasks: 38
Memory: 485.2M
CGroup: /system.slice/mysqld3306.service
└─1108951 /usr/local/mysql/bin/mysqld --defaults-file=/data/3306/my.cnf
12月 29 18:22:54 kylin systemd[1]: Started MySQL Server.
#登录数据库
[root@kylin backup]# mysql -uroot -p -S /tmp/mysql3306.sock
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| oldboy |
| performance_schema |
| school |
| sys |
| test01 |
| test_sync |
| world |
| xiabai |
| xiaoA |
| xiaobai |
+--------------------+
12 rows in set (0.01 sec)数据库主从同步架构搭建
主从架构介绍
主从同步架构搭建作用:
1)实现数据信息实时备份,以及用于修复数据
主库物理损坏 从库做数据恢复
主库逻辑损坏 从库做数据恢复(延迟从库)
2)可以实现数据库高可用架构搭建
3)可以实现数据库读写分离架构搭建
主从同步架构搭建原理:
数据库主从同步时,需要应用到4个文件和3个线程;
利用这个4个文件和3个线程就可以实现主从同步
其中4个文件为:
- binlog文件: 记录主库操作事务信息
- relaylog文件: 在从库中保存binlog事务信息
- master-info文件: 记录连接主库配置(地址 端口 用户名 密码)/记录同步主库数据位置点和binlog文件信息
- relaylog-info文件:加载relaylog语句信息的位置点
其中还有3个线程:
- dump线程:主库
1)负责监控binlog日志信息变化
2)将binlog日志中事务信息传输给IO线程
3)dump负责和从库IO线程进行会话保持
- IO线程: 从库
1)负责和主库建立会话连接
2)接收主库的binlog的事务信息保存到relaylog文件中
3)会负责将新的binlog事务的位置点信息更新到master-info文件中
- SQL线程: 从库
1)读取relaylog文件中数据信息,进行SQL语句的执行(回放)
2)会记录relaylog回放事务的位置点到relaylog-info文件中,断点续传。
文件记忆口诀
binlog 主库记台账,relaylog 从库待办账;
master-info 记对接,relaylog-info 记进度。
线程记忆口诀
主库 dump 传信员,盯账传信保联系;
从库 IO 收件员,连主存本记位置;
从库 SQL 办事员,读本办事记进度。
完整同步流程
总公司(主库)做业务操作(增删改),立刻记到「正式台账」(binlog)里;
总公司传信员(dump 线程)盯着台账,只要有新内容,就等着分公司对接;
分公司收件员(IO 线程)先拨通传信员电话(建立连接),把新的台账内容抄到自己的「待办本」(relaylog),同时更新「对接记录本」(master-info):“总公司台账抄到第 X 页了”;
分公司办事员(SQL 线程)拿着「待办本」,照着上面的内容一步步做(执行 SQL),做完后更新「办事进度本」(relaylog-info):“待办本办到第 Y 页了”;
传信员和收件员全程保持通话,总公司有新操作,分公司能实时收到、实时执行,最终分公司和总公司数据完全一致。
主从架构搭建
步骤一:创建主从数据库服务
[root@主数据库51 ~]# vim /data/3306/my.cnf
[mysqld]
server_id=1
user=mysql
port=3306
datadir=/data/3306/data
basedir=/usr/local/mysql
socket=/tmp/mysql3306.sock
character-set-server=utf8mb3
general_log=on
general_log_file=/data/3306/logs/general.log
log_error=/data/3306/logs/error.log
log_bin=/data/3306/logs/binlog
[root@从数据库52 ~]# vim /data/3306/my.cnf
[mysqld]
server_id=2
# 核心配置:0=MySQL启动时自动启动slave同步,1=不自动启动(默认)
skip_slave_start = 0
user=mysql
port=3306
datadir=/data/3306/data
basedir=/usr/local/mysql
socket=/tmp/mysql3306.sock
character-set-server=utf8mb3
general_log=on
general_log_file=/data/3306/logs/general.log
log_error=/data/3306/logs/error.log
log_bin=/data/3306/logs/binlog
步骤二:在主库中需要进行备份数据
mysqldump -uroot -p -S /tmp/mysql3306.sock -A --single-transaction --source-data >/data/all.sql
scp -rp /data/all.sql root@172.16.1.52:/backup
步骤三:在从库中需要进行数据恢复
mysql -u root -p -S /tmp/mysql3306.sock </backup/all.sql
步骤四:在主库中创建同步用户
create user repl@'10.0.0.%' identified with mysql_native_password by '123456';
grant replication slave on *.* to repl@'10.0.0.%';
步骤五:在从库 进行主从同步配置
#查看位置点
[root@db52 ~]# head -30 /backup/all.sql
CHANGE MASTER TO MASTER_LOG_FILE='binlog.000011', MASTER_LOG_POS=157;
#在mysql中同步命令
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='binlog.000011',
MASTER_LOG_POS=157,
MASTER_CONNECT_RETRY=10;
步骤六:启动主从同步功能
mysql> start slave;
Query OK, 0 rows affected, 1 warning (0.02 sec)
#验证:
SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 10.0.0.51
Master_User: repl
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000012
Read_Master_Log_Pos: 384
Relay_Log_File: db52-relay-bin.000004
Relay_Log_Pos: 594
Relay_Master_Log_File: binlog.000012
Slave_IO_Running: Yes #确保yes
Slave_SQL_Running: Yes #确保yes
测试同步:
从库:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| oldboy |
| performance_schema |
| pxb |
| school |
| sys |
| world |
| xiabai |
| xiaoA |
| xiaobai |
+--------------------+
11 rows in set (0.01 sec)
主库:
CREATE DATABASE IF NOT EXISTS test_sync;
CREATE TABLE IF NOT EXISTS t1 (id INT PRIMARY KEY, name VARCHAR(20));
INSERT INTO t1 VALUES (1, 'sync_success'), (2, 'master_slave_ok');
从库:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| oldboy |
| performance_schema |
| pxb |
| school |
| sys |
| test_sync |
| world |
| xiabai |
| xiaoA |
| xiaobai |
+--------------------+
12 rows in set (0.00 sec)
同步成功
什么是GTID全局事务编号?
1.会为每个数据库实例分配一个唯一UUID实例编号
[root@kylin ~]# cat /data/3306/data/auto.cnf
[auto]
server-uuid=56549737-e4a0-11f0-84f9-000c29f08bc6
2.每完成一个事务信息,会给每个事务进行分配一个编号(唯一)
搭建过程:
步骤一:编写数据库GTID功能并加载激活GTID功能(主从都要设置)
vim /data/3306/my.cnf
server_id= #注意修改id,主从不要一致
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
#检查是否开启
[root@kylin ~]# mysql -uroot -p -S /tmp/mysql3306.sock -e "select @@gtid_mode"
Enter password:
+-------------+
| @@gtid_mode |
+-------------+
| ON | #on为打开off为关闭
+-------------+
步骤二:创建备份数据并在从库恢复备份数据
#先去数据库中看一下是否有GTID,我们需要在主库中完成一个事务操作,生成一个Gtid
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000018 | 157 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
#随便创建/删除库,刷新事务,生成GTID
mysql> drop database test01;
Query OK, 1 row affected (0.05 sec)
mysql> show master status;
+---------------+----------+--------------+------------------+----------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+----------------------------------------+
| binlog.000018 | 344 | | | 56549737-e4a0-11f0-84f9-000c29f08bc6:1 |
+---------------+----------+--------------+------------------+----------------------------------------+
1 row in set (0.00 sec)
#全量备份,传输给从库
mysqldump -uroot -p -S /tmp/mysql3306.sock -A --source-data --single-transaction >/backup/all.sql
scp -rp /backup/all.sql root@10.0.0.52:/backup/
说明:
--set-gtid-purged=ON 备份含 GTID,恢复校验 GTID 主从迁移 / 主从环境的恢复 让从库和主库 GTID 对齐,避免重复同步事务
--set-gtid-purged=OFF 备份无 GTID,恢复只执行 SQL 单机数据恢复、误操作后的数据修复 跳过 GTID 校验,强制重新执行 SQL,解决 “已执行 GTID 事务被跳过” 的恢复异常问题
恢复后要接主从 → 用ON;
只是单纯恢复数据(不管主从)→ 用OFF。
步骤三:从库通过主库的全量备份文件,恢复数据
mysql -uroot -S /tmp/mysql3306.sock </backup/all.sqlv
步骤四:在主库中设置主从用户
create user repl@'10.0.0.%' identified with mysql_native_password by '123456';
grant replication slave on *.* to repl@'10.0.0.%';
步骤五:在从库中做主从功能配置
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='123456',
master_auto_position=1,
MASTER_CONNECT_RETRY=10;
步骤六:启动主从同步功能
start slave;
#验证:
SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Retrieved_Gtid_Set: 56549737-e4a0-11f0-84f9-000c29f08bc6:2
Executed_Gtid_Set: 56549737-e4a0-11f0-84f9-000c29f08bc6:1-2
------------------------------------------------
注意事项:
1)主库需要生成GTID事务编号
2)在从库中不要进行写入操作
#在my.cnf中配置:read_only=1
3)确保主从数据库server_UUID和server_id两个编号信息不要一致
数据库主从同步架构扩展
1. 延迟从库
作用:利用延迟从库同步功能,进行主库数据修复(主库的物理和逻辑损坏都可以恢复)
原理:在从库上控制 SQL 线程,延迟指定时间再对 relaylog 中的事务信息做回放
步骤一:确保部署好正常的主从同步数据库
....
步骤二:调整从库主从配置信息,实现延迟同步
stop slave;
change master to master_delay=300; #延迟300秒
start slave;
查询:mysql> SHOW SLAVE STATUS\G
SQL_Delay: 300
主库物理损坏(硬件)
步骤一:模拟正常主库事务操作和数据库服务停止
mysql> insert into t1 values (4),(5),(6);
systemctl stop mysqld3306
步骤二:在从库中需要快速回放完整数据信息
stop slave SQL_THREAD;
change master to master_delay=0;
start slave SQL_THREAD;
步骤三:利用物理备份或逻辑备份完成数据恢复
.....
主库逻辑损坏(误操作)
步骤一:模拟误操作
create table t1
mysql> insert into t1 values (7),(8),(9); -- 正常操作
mysql> update t1 set id=10 where id>4 and id<10; -- 误操作
步骤二:利用从库实现数据修复
stop slave SQL_THREAD; -- 停止SQL线程,但不停止IO线程
1)SQL线程此时不要再加载relaylog日志信息,进行回放数据,从而避免把错误事务做回放
2)IO线程还可以继续同步正确事务操作信息
change master to master_delay=0;
start slave until sql_before_gtids="55d9eef4-e25f-11f0-86e5-000c29a6b7cc:11";
步骤三:将正常从库回放数据做备份/在主库中进行数据修复
...逻辑备份与恢复
-------------------------------------------------------------------------------------
如果做的误操作是将数据库或表删除了,如何进行数据修复?(基于事务编号的主从,配置了延迟从库)
场景 1:误操作事务未在从库执行(延迟窗口内)
步骤 1:紧急停止从库 SQL 线程(保留 IO 线程,避免丢新数据)
STOP SLAVE SQL_THREAD; -- 仅停SQL线程(回放事务),IO线程继续拉取主库binlog,不丢失新数据 -- 验证状态:Slave_SQL_Running: No,Slave_IO_Running: Yes
步骤 2:恢复误删的库 / 表数据(2 种方式)
方式 1:直接从延迟从库导出数据(最快)
从库因 SQL 线程暂停,仍保留误删前的库 / 表数据,直接用mysqldump导出:
# 导出整个库(误删库场景) mysqldump -uroot -p -S /tmp/mysql.sock 误删库名 > /data/恢复库名.sql # 导出单表(误删表场景) mysqldump -uroot -p -S /tmp/mysql.sock 库名 误删表名 > /data/恢复表名.sql
方式 2:将从库同步到误操作前的位置(精准恢复)
若从库已有部分新事务,需让从库回放至误操作前的位置:
-- GTID环境:同步到误操作GTID的前一个事务(如误操作GTID是uuid:100,同步到uuid:99)
CHANGE MASTER TO
MASTER_AUTO_POSITION=0,
MASTER_LOG_FILE='binlog.000100', -- 误操作所在的binlog文件
MASTER_LOG_POS=1230; -- 误操作位置的前一个位置(如误操作Pos:1234,填1230)
START SLAVE SQL_THREAD; -- 回放至该位置后自动停止(或手动停)
步骤 3:恢复数据到主库 / 业务
将导出的 sql 文件导入主库(或业务需要的实例):
mysql -uroot -p -S /tmp/mysql.sock 目标库名 < /data/恢复库名.sql
步骤 4:重置从库同步(跳过误操作事务)
-- GTID环境:跳过误操作的GTID(如uuid:100)
SET GTID_NEXT='uuid:100';
BEGIN; COMMIT; -- 空事务占用该GTID,从库执行时会跳过
SET GTID_NEXT='AUTOMATIC';
-- 重启SQL线程
START SLAVE SQL_THREAD;
-- 非GTID环境:跳过1个事务(误操作是1个事务则填1)
SET GLOBAL sql_slave_skip_counter=1;
START SLAVE SQL_THREAD;
场景 2:误操作事务已在从库执行(延迟窗口过了)
步骤 1:停从库所有同步(防止数据覆盖)
STOP SLAVE; -- 停IO+SQL线程
步骤 2:找从库的全量备份(或用从库当前数据做临时备份)
# 先对从库当前数据做临时备份(防止操作失误)
mysqldump -uroot -p -S /tmp/mysql.sock -A --single-transaction > /data/延迟从库临时备份.sql
步骤 3:解析从库 relay log/binlog,提取误操作前的所有数据
从库的relay log(中继日志)保留了主库推送的所有事务,解析到误操作前的位置:
# 解析relay log,导出误操作前的所有事务(如误操作Pos:1234)
mysqlbinlog --no-defaults --stop-position=1230 /var/lib/mysql/从库relay log文件名 > /data/恢复到误操作前.sql
步骤 4:恢复数据
# 先清空误删后的库/表(谨慎!确认无有用数据)
mysql -uroot -p -e "DROP DATABASE IF EXISTS 误删库名;"
# 导入恢复文件
mysql -uroot -p < /data/恢复到误操作前.sql
步骤 5:重新搭建延迟从库(可选)
数据恢复后,建议重新配置延迟从库(避免旧事务干扰):
-- 重置从库同步
RESET SLAVE ALL;
-- 重新配置主从,恢复延迟(如延迟300秒)
CHANGE MASTER TO
MASTER_HOST='主库IP',
MASTER_USER='repl',
MASTER_PASSWORD='密码',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1;
-- 设置延迟300秒
SET GLOBAL SQL_SLAVE_SKIP_COUNTER=0;
CHANGE MASTER TO MASTER_DELAY=300;
START SLAVE;
#前提:开启基于事务编号的主从同步+延迟从库
#查看主库应用日志文件和事件位置点情况
mysql> show master status;
+---------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+------------------------------------------+
| binlog.000018 | 535 | | | 56549737-e4a0-11f0-84f9-000c29f08bc6:1-2 |
+---------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.01 sec)
#主库模拟删除操作
create database relaydb;
use relaydb;
create table t1 (id int);
insert into t1 values(1),(2),(3);
commit;
insert into t1 values(11),(12),(13);
commit;
insert into t1 values(111),(112),(113);
commit;
drop database relaydb;
#再次查看查看主库应用日志文件和事件位置点情况
mysql> show master status;
+---------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+------------------------------------------+
| binlog.000018 | 1981 | | | 56549737-e4a0-11f0-84f9-000c29f08bc6:1-8 |
+---------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.01 sec)
#查看从库应用日志文件和事件位置点情况
mysql> show slave status\G
*************************** 1. row ***************************
Master_Log_File: binlog.000018
Read_Master_Log_Pos: 1981
Relay_Log_File: db52-relay-bin.000002
Relay_Log_Pos: 411
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
SQL_Delay: 300
SQL_Remaining_Delay: 239
--------从库开始操作----------------------------------------------------
操作1:停止从库SQL线程回放日志事件
mysql> stop slave sql_thread;
mysql> show slave status\G
*************************** 1. row ***************************
Master_Log_File: binlog.000018
Read_Master_Log_Pos: 1981
Relay_Log_File: db52-relay-bin.000002
Relay_Log_Pos: 411
Relay_Master_Log_File: binlog.000018
Slave_IO_Running: Yes
Slave_SQL_Running: No
SQL_Delay: 300
SQL_Remaining_Delay: NULL
操作2:回放日志事件在异常操作位置点前,找到异常操作日志文件信息和事件位置点信息
mysql> show relaylog events in 'db52-relay-bin.000002';
+-----------------------+------+----------------+-----------+-------------+-------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+-----------------------+------+----------------+-----------+-------------+-------------------------------------------------------------------+
| db52-relay-bin.000002 | 4 | Format_desc | 2 | 126 | Server ver: 8.0.36, Binlog ver: 4 |
| db52-relay-bin.000002 | 126 | Previous_gtids | 2 | 157 | |
| db52-relay-bin.000002 | 157 | Rotate | 1 | 0 | binlog.000018;pos=4 |
| db52-relay-bin.000002 | 201 | Format_desc | 1 | 126 | Server ver: 8.0.36, Binlog ver: 4 |
| db52-relay-bin.000002 | 323 | Rotate | 0 | 0 | binlog.000018;pos=157 |
| db52-relay-bin.000002 | 367 | Rotate | 0 | 0 | binlog.000018;pos=535 |
| db52-relay-bin.000002 | 411 | Gtid | 1 | 612 | SET @@SESSION.GTID_NEXT= '56549737-e4a0-11f0-84f9-000c29f08bc6:3' |
| db52-relay-bin.000002 | 488 | Query | 1 | 729 | create database relaydb /* xid=1998 */ |
| db52-relay-bin.000002 | 605 | Gtid | 1 | 806 | SET @@SESSION.GTID_NEXT= '56549737-e4a0-11f0-84f9-000c29f08bc6:4' |
| db52-relay-bin.000002 | 682 | Query | 1 | 924 | use `relaydb`; create table t1 (id int) /* xid=2003 */ |
| db52-relay-bin.000002 | 800 | Gtid | 1 | 1003 | SET @@SESSION.GTID_NEXT= '56549737-e4a0-11f0-84f9-000c29f08bc6:5' |
| db52-relay-bin.000002 | 879 | Query | 1 | 1081 | BEGIN |
| db52-relay-bin.000002 | 957 | Table_map | 1 | 1132 | table_id: 264 (relaydb.t1) |
| db52-relay-bin.000002 | 1008 | Write_rows | 1 | 1182 | table_id: 264 flags: STMT_END_F |
| db52-relay-bin.000002 | 1058 | Xid | 1 | 1213 | COMMIT /* xid=2004 */ |
| db52-relay-bin.000002 | 1089 | Gtid | 1 | 1292 | SET @@SESSION.GTID_NEXT= '56549737-e4a0-11f0-84f9-000c29f08bc6:6' |
| db52-relay-bin.000002 | 1168 | Query | 1 | 1370 | BEGIN |
| db52-relay-bin.000002 | 1246 | Table_map | 1 | 1421 | table_id: 264 (relaydb.t1) |
| db52-relay-bin.000002 | 1297 | Write_rows | 1 | 1471 | table_id: 264 flags: STMT_END_F |
| db52-relay-bin.000002 | 1347 | Xid | 1 | 1502 | COMMIT /* xid=2006 */ |
| db52-relay-bin.000002 | 1378 | Gtid | 1 | 1581 | SET @@SESSION.GTID_NEXT= '56549737-e4a0-11f0-84f9-000c29f08bc6:7' |
| db52-relay-bin.000002 | 1457 | Query | 1 | 1659 | BEGIN |
| db52-relay-bin.000002 | 1535 | Table_map | 1 | 1710 | table_id: 264 (relaydb.t1) |
| db52-relay-bin.000002 | 1586 | Write_rows | 1 | 1760 | table_id: 264 flags: STMT_END_F |
| db52-relay-bin.000002 | 1636 | Xid | 1 | 1791 | COMMIT /* xid=2008 */ |
| db52-relay-bin.000002 | 1667 | Gtid | 1 | 1868 | SET @@SESSION.GTID_NEXT= '56549737-e4a0-11f0-84f9-000c29f08bc6:8' |
| db52-relay-bin.000002 | 1744 | Query | 1 | 1981 | drop database relaydb /* xid=2010 */ |
+-----------------------+------+----------------+-----------+-------------+-------------------------------------------------------------------+
27 rows in set (0.14 sec)
操作3:在从库重启进行日志回放操作前,关闭从库延迟回放的功能
mysql> change master to master_delay=0;
操作4:开启了GTID功能,按照GTID位置点进行数据信息回放
mysql> start slave until sql_before_gtids="56549737-e4a0-11f0-84f9-000c29f08bc6:8";
mysql> show slave status\G
*************************** 1. row ***************************
Master_Log_File: binlog.000018
Read_Master_Log_Pos: 1981
Relay_Log_File: db52-relay-bin.000002
Relay_Log_Pos: 1667
Relay_Master_Log_File: binlog.000018
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
SQL_Delay: 0
SQL_Remaining_Delay: NULL
#操作5:核实异常数据信息是否恢复
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| oldboy |
| performance_schema |
| relaydb |
| school |
| sys |
| test01 |
| test_sync |
| world |
| xiabai |
| xiaoA |
| xiaobai |
+--------------------+
13 rows in set (0.12 sec)
mysql> stop slave;
-----------------------------------------------------
用mysqldump导出relaydb
[root@db52 ~]# mysqldump -uroot -S /tmp/mysql3306.sock --single-transaction --databases relaydb > /backup/relaydb_restore.sql
Warning: A partial dump from a server that has GTIDs will by default include the GTIDs of all transactions, even those that changed suppressed parts of the database. If you don't want to restore GTIDs, pass --set-gtid-purged=OFF. To make a complete dump, pass --all-databases --triggers --routines --events.
# 验证导出文件完整性
cat /data/relaydb_restore.sql | grep -E "CREATE DATABASE|INSERT INTO" # 能看到建库、插数据语句即正常
scp -rp /data/relaydb_restore.sql root@10.0.0.51:/backup
#主库:
[root@kylin backup]# mysql -uroot -p -S /tmp/mysql3306.sock < /backup/relaydb_restore.sql
Enter password:
ERROR 3546 (HY000) at line 24: @@GLOBAL.GTID_PURGED cannot be changed: the added gtid set must not overlap with @@GLOBAL.GTID_EXECUTED
导出的relaydb_restore.sql备份文件中包含SET @@GLOBAL.GTID_PURGED语句,而主库的@@GLOBAL.GTID_EXECUTED已经包含了这些 GTID(主库本身就是这些 GTID 的 “源头”),MySQL 禁止修改GTID_PURGED为与GTID_EXECUTED重叠的集合(因为 GTID 是全局唯一的,执行过的事务不能重复标记为 “已清理”)。
解决:
#先查看数据库当前GTID位置点
mysql> SHOW GLOBAL VARIABLES LIKE 'GTID_EXECUTED';
+---------------+------------------------------------------+
| Variable_name | Value |
+---------------+------------------------------------------+
| gtid_executed | 56549737-e4a0-11f0-84f9-000c29f08bc6:1-8 |
+---------------+------------------------------------------+
1 row in set (0.04 sec)
#过滤一下备份文件查看是否有重复部分
[root@kylin backup]# grep -n "GTID_PURGED" /backup/relaydb_restore.sql
24:#SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '065bcff0-e520-11f0-b4fa-000c294f11cd:1,
#将下面两条注释
[root@kylin backup]# vim /backup/relaydb_restore.sql
#SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '065bcff0-e520-11f0-b4fa-000c294f11cd:1,
#56549737-e4a0-11f0-84f9-000c29f08bc6:1-7';
#再尝试恢复
[root@kylin backup]# mysql -uroot -p -S /tmp/mysql3306.sock < /backup/relaydb_restore.sql
Enter password:
[root@kylin backup]# mysql -uroot -p -S /tmp/mysql3306.sock
Enter password:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| oldboy |
| performance_schema |
| relaydb |
| school |
| sys |
| test01 |
| test_sync |
| world |
| xiabai |
| xiaoA |
| xiaobai |
+--------------------+
13 rows in set (0.01 sec)
-------------------------------------------------------------
后续:
从库重新连接主库(配置回原来的GTID+延迟从库)
步骤 1:在从库跳过误操作的 GTID(避免再次执行 drop)
-- 从库执行:先设置GTID_NEXT为误操作的GTID,执行空事务“占用”该GTID
SET GTID_NEXT='56549737-e4a0-11f0-84f9-000c29f08bc6:8';
BEGIN; COMMIT; -- 空事务,从库后续同步时会跳过该GTID
SET GTID_NEXT='AUTOMATIC'; -- 恢复自动GTID分配
步骤 2:重置从库同步配置(清理旧的 relay log 和同步信息)
-- 从库执行:重置所有同步状态(清理relay log、master info)
RESET SLAVE ALL; -- 注意:MySQL 5.7+支持,5.6用RESET SLAVE(需先STOP SLAVE)
步骤 3:重新配置主从连接(基于 GTID)
-- 从库执行:指定主库信息+GTID自动同步
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='123456',
master_auto_position=1,
MASTER_CONNECT_RETRY=10;
步骤 4:重新设置延迟并启动同步
-- 从库执行:恢复延迟300秒(和之前的延迟配置一致)
change master to master_delay=300; #延迟300秒
-- 启动主从同步(IO+SQL线程)
start slave;
步骤 5:验证从库同步状态
-- 从库执行:检查同步状态
#验证:
SHOW SLAVE STATUS\G
-- 关键验证项:
-- 1. Slave_IO_Running: Yes (IO线程正常拉取主库binlog)
-- 2. Slave_SQL_Running: Yes (SQL线程正常回放,且跳过了GTID:8)
-- 3. SQL_Delay: 300 (延迟配置生效)
-- 4. Seconds_Behind_Master: 约300 (延迟正常,主库新事务会延迟300秒执行)
-- 5. Executed_Gtid_Set: 包含56549737-e4a0-11f0-84f9-000c29f08bc6:1-7
2. 主从同步方式
纯异步模式
MySQL 主从复制 默认是纯异步模式
异步复制的完整流程(默认行为):
主库执行事务 → 写入 binlog → 立即给客户端返回 “执行成功”(不管从库);
从库 IO 线程主动向主库 dump 线程请求 binlog;
主库 dump 线程把 binlog 推给从库 IO 线程;
从库 IO 线程把 binlog 写入 relay log → 但不会给主库 dump 线程任何 “确认消息”;
从库 SQL 线程异步读取 relay log,重放事务。
半同步模式
半同步是 MySQL 5.5 之后新增的增强模式(需安装 / 开启半同步插件),核心是IO线程给“主库 dump 线程”加了一个 “等待确认” 的规则:
半同步复制的流程(开启插件后):
主库执行事务 → 写入 binlog;
主库 dump 线程把 binlog 推给从库 IO 线程;
从库 IO 线程接收 binlog → 写入 relay log → 立即给主库 dump 线程返回一个 ACK 确认包(表示 “我已经收到并落地 relay log 了”);
主库 dump 线程收到 ACK 后,才给客户端返回 “执行成功”;
(如果超时没收到 ACK,主库会降级为异步模式,不再等待);
从库 SQL 线程依然异步重放 relay log(半同步只保证 “binlog 传到从库并落地”,不保证 “从库执行完事务”)。
步骤一:安装半同步复制插件(主库、从库分别操作)
主库执行(安装主库半同步插件):
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
从库执行(安装从库半同步插件):
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
验证插件安装:show plugins;
rpl_semi_sync_slave | ACTIVE | REPLICATION | semisync_slave.so | GPL
步骤二:激活半同步复制功能(临时 + 永久生效)
临时激活(立即生效,MySQL 重启后失效)
主库执行:
SET GLOBAL rpl_semi_sync_master_enabled = 1;
从库执行:需重启 IO 线程,使半同步配置生效
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;
永久生效(修改配置文件,重启后保留)
主库:编辑 MySQL 配置文件(如/etc/my.cnf、/etc/mysql/my.cnf),添加以下内容:
[mysqld]
rpl_semi_sync_master_enabled = 1 # 启用主库半同步
rpl_semi_sync_master_timeout = 5000 # 可选:等待从库ACK的超时时间(单位:毫秒,超时降级为异步)
从库:编辑 MySQL 配置文件,添加以下内容:
[mysqld]
rpl_semi_sync_slave_enabled = 1 # 启用从库半同步
重启主库、从库的 MySQL 服务:
systemctl restart mysqld3306.service
步骤三:验证半同步是否正常工作
主库执行,结果应为ON表示半同步已启用并运行:
-- 验证半同步功能是否开启
SHOW GLOBAL VARIABLES LIKE 'rpl_semi_sync_master_enabled';
-- 验证半同步是否处于工作状态
mysql> SHOW GLOBAL STATUS LIKE 'Rpl_semi_sync_master_status';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| Rpl_semi_sync_master_status | ON |
+-----------------------------+-------+
1 row in set (0.02 sec)
全同步模式
主库执行一个事务后,必须等待至少一个从库的 SQL 线程完全执行完该事务(不仅要收到 binlog、写入 relay log,还要把事务重放落地到从库磁盘),主库才会给客户端返回 “事务提交成功”。
全同步复制的完整执行流程
客户端向主库提交事务(如
insert/update);主库执行事务逻辑 → 写入本地 binlog;
主库 dump 线程将该事务的 binlog 推送给从库 IO 线程;
从库 IO 线程接收 binlog → 写入本地 relay log;
从库 SQL 线程读取 relay log → 执行该事务(落地到从库的数据文件,如 InnoDB 的 ibd 文件);
从库 SQL 线程执行完成后,向主库返回 “事务执行完成” 的确认(Full ACK);
主库收到这个 Full ACK 后,才给客户端返回 “事务提交成功”;
若超时未收到从库的 Full ACK,全同步通常会降级(如拒绝提交 / 降级为半同步,具体看实现)。
3. 主从监控与故障处理
主从监控信息:
读取:show slave status\G 中的信息
状态信息:
Slave_IO_Running: Yes #写脚本监控两个 yes 是否小于 2 个
Slave_SQL_Running: Yes
Last_Errno: 0 #IO 的错误编码
Last_Error: #IO 的错误信息
Last_SQL_Errno: 0 #SQL 的错误编码
Last_SQL_Error: #SQL 的错误原因
延迟信息:
Seconds_Behind_Master: 0 #主从延迟问题,值越大越需要关注 >40~50 报警
Master_Log_File: binlog.000018 #IO 线程接收到最新的 binlog 文件信息
Read_Master_Log_Pos: 535 #IO 线程识别到最新事务的位置点信息
Relay_Master_Log_File: binlog.000018 #SQL 线程读取到最新的 binlog 文件信息
Exec_Master_Log_Pos: 535 #SQL 线程回放到最新事务的位置点信息
#如果配置了 GTID
Retrieved_Gtid_Set: 56549737-e4a0-11f0-84f9-000c29f08bc6:2 #IO 线程接收到的事务编号信息
Executed_Gtid_Set: 56549737-e4a0-11f0-84f9-000c29f08bc6:1-2 #SQL 线程回放到的最新务编号信息
其它主从状态信息:
replicate_do_db = xiaoA
replicate_ignore_db = xiaoA
replicate_do_table = oldboy_db.oldboy_user #只重放oldboy_db库下oldboy_user表的事务
replicate_do_table = oldboy_db.oldboy_order #可配置多个,用换行/逗号分隔
replicate_wild_do_table = oldboy_%.% #重放所有以“oldboy_”开头的库下的所有表的事务
replicate_wild_do_table = test_db.user_% #重放test_db库下以“user_”开头的表的事务
SQL_Delay: 300 #已开启延迟从库功能,拖延时间的信息
SQL_Remaining_Delay: NULL #延时的倒计时时间
故障处理:
关于 IO 状态:
connecting
-- 连接地址、端口、用户、密码信息错误,可能导致连接异常;
-- 防火墙安全策略拦截连接、网络通讯配置异常,影响连接建立;
-- 主库达到数据库服务连接数上限,造成主从连接产生异常;
no
-- IO 线程请求主库日志时失败,可能是主库对应的 binlog 日志被无意清理;
-- 主从实例的 server-id 或 server-uuid 配置重复,导致 IO 线程请求日志失败;
关于SQL状态:
no
- 无法正常读取relaylog日志文件,可能需要读取relaylog文件损坏丢失
如果从库relaylog文件没有做备份,无法将损坏丢失relaylog文件修复,可以重新生成relaylog
在从库中做以下操作
stop slave;
确认SQL线程最后读取relaylog事务信息位置点
show slave status;
Relay_Master_Log_File: binlog.000028
Exec_Master_Log_Pos: 3510
reset slave all; -- 将master_info中主从配置信息删除
change master to -- 重新做主从配置
位置点位置:binlog.000028 3510
start slave
- 已经正常读取relaylog日志文件,但是无法回放日志中的事务语句
无法回放事务中SQL语句原因
1)回放SQL语句重复了,所以无法进行回放
可以将重复数据信息删除,drop/delete
可以忽略重复数据信息, set global slave_skip_errors=1007
2)主从数据库版本不一致,但是同步一些SQL语句无法执行
insert into t1 values ('xiaoA','0000-00-00') 8.0 无法
避免主从数据库实例版本不一致
3)主从数据库的表结构信息不一致(字段 数据类型 约束索引)
确保主从数据表结构一致
4)主从之间出现延迟情况(有些语句没有发送到从库),也会导致SQL线程异常
主库 create table t1 -没有发送给IO线程->
主库 insert into t1 values(xxx) -已经发送给IO线程->
5)搭建数据架构应用不合理(有些语句没有发送到从库),也会导致SQL线程异常
高可用架构进行应用时,没有数据补偿功能,架构应用不合理
数据库实现双主应用,没有应用合理设计,会导致双主之间数据同步异常
无法回放事务 SQL 语句的原因及处理:
1) 回放 SQL 语句重复
现象:重复执行 SQL 导致无法回放
处理:删除重复数据(drop/delete)
忽略重复错误:set global slave_skip_errors=1007
2) 主从数据库版本不一致
示例:主从版本差异导致 SQL 无法执行(如 8.0 版本执行insert into t1 values ('xiao','0000-00-00')失败,5.6 版本可以执行)
说明:主从版本不一致难以完全避免
3)主从数据库表结构不一致
差异点:字段、数据类型、约束、索引
处理:确保主从数据表结构一致
4)主从之间存在延迟
影响:延迟会导致 SQL 线程异常(延迟期间若主库发生数据变更 + 从库被人为写入,会引发 “主从数据冲突”,进而导致 SQL 线程执行失败)
5)搭建数据库架构应用不合理(有些语句没有发送到从库),也会导致 SQL 线程异常
高可用架构进行应用时,没有数据补偿功能,架构应用不合理(主备高可用)
互为主从(双主)架构,会导致双主之间数据同步异常( 双主架构若没做 “主键自增步长分离”(如主 1 用奇数 ID、主 2 用偶数 ID),会出现 “双主同时插入相同主键”,导致对方同步时 SQL 线程因主键冲突报错,属于典型的双主架构设计缺陷。)
补充知识:实现数据库克隆方式建立主从同步
1)数据量比较大,迁移数据过程会比较耗费时间,为了加快迁移数据效率,可以使用克隆的方式
2)克隆迁移数据,可以实现传统数据库服务数据上云
克隆搭建主从注意事项
1. 克隆前暂停主库大事务(避免克隆过程中数据大量变更);
2. 克隆完成后校验数据一致性(用pt-table-checksum);
3. 云环境克隆需确保网络互通(自建库放行云服务器IP);
4. 克隆后及时开启主从同步,避免数据差异扩大。
补充:主从同步故障排查流程(标准化步骤)
1. 执行`SHOW SLAVE STATUS\G`,确认IO/SQL线程状态、错误码/错误信息;
2. 针对IO线程异常:优先排查网络、账号、server-id、binlog是否存在;
3. 针对SQL线程异常:优先核对错误信息中的关键词(如主键冲突、表结构不一致),定位具体事务;
4. 临时恢复同步(如跳过错误),但必须事后校验数据一致性;
5. 优化架构/配置,避免同类故障重复发生;
6. 记录故障处理过程,更新监控规则(如新增错误码告警)。
总结
主从同步故障的核心是“预防大于处理”:
- 监控层面:覆盖线程状态、延迟、错误码,设置合理阈值;
- 配置层面:统一主从版本/表结构/参数,禁止从库写入,优化架构设计;
- 应急层面:标准化排查流程,优先恢复同步再根治问题,事后校验数据一致性;
- 迁移层面:大数量级场景优先使用克隆方式,提升主从搭建效率。一、主从监控信息
读取主从同步状态的核心指令:show slave status\G
信息解读:
监控脚本:
#!/bin/bash
# 功能:监控主从同步状态,异常则告警
MYSQL_CMD="mysql -uroot -p'你的密码' -S /tmp/mysql.sock -e"
SLAVE_STATUS=$($MYSQL_CMD "SHOW SLAVE STATUS\G" | grep -E 'Slave_IO_Running|Slave_SQL_Running|Seconds_Behind_Master|Last_SQL_Errno')
# 提取关键状态
IO_STATUS=$(echo "$SLAVE_STATUS" | grep 'Slave_IO_Running' | awk '{print $2}')
SQL_STATUS=$(echo "$SLAVE_STATUS" | grep 'Slave_SQL_Running' | awk '{print $2}')
DELAY=$(echo "$SLAVE_STATUS" | grep 'Seconds_Behind_Master' | awk '{print $2}')
SQL_ERRNO=$(echo "$SLAVE_STATUS" | grep 'Last_SQL_Errno' | awk '{print $2}')
# 告警逻辑
ALERT_MSG=""
if [ "$IO_STATUS" != "Yes" ] || [ "$SQL_STATUS" != "Yes" ]; then
ALERT_MSG="主从同步线程异常:IO=$IO_STATUS, SQL=$SQL_STATUS"
elif [ "$DELAY" -gt 50 ] && [ "$DELAY" != "NULL" ]; then
ALERT_MSG="主从延迟过高:$DELAY秒"
elif [ "$SQL_ERRNO" -ne 0 ]; then
ALERT_MSG="SQL线程错误:错误码$SQL_ERRNO,详情请查Last_SQL_Error"
fi
# 发送告警(示例:钉钉/邮件,可替换为企业微信、短信等)
if [ -n "$ALERT_MSG" ]; then
echo "$(date +%F\ %T) $ALERT_MSG" >> /var/log/mysql_slave_monitor.log
# 钉钉告警示例(需提前配置钉钉机器人)
curl 'https://oapi.dingtalk.com/robot/send?access_token=你的token' \
-H 'Content-Type: application/json' \
-d "{\"msgtype\":\"text\",\"text\":{\"content\":\"$ALERT_MSG\"}}"
fi二、常见故障分类与处理方案
1. IO 线程异常(Slave_IO_Running: Connecting/No)
(1)状态:Connecting(连接中失败)
核心原因:从库无法连接主库获取 binlog
(2)状态:No(IO 线程停止)
核心原因:IO 线程拉取 binlog 失败
2. SQL 线程异常(Slave_SQL_Running: No)
(1)事务回放重复(主键 / 唯一键冲突)
现象:Last_SQL_Error 包含 “Duplicate entry”,如 “Duplicate entry '123' for key 'PRIMARY'”原因:从库已有相同主键数据,主库同步的 INSERT/UPDATE 语句冲突处理方案:
临时忽略错误(紧急恢复同步,需事后核对数据):sql
# 方式1:忽略单次错误(推荐)
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; # 跳过下一个事务
START SLAVE SQL_THREAD;
# 方式2:永久忽略指定错误码(谨慎,仅用于确认无害的错误)
# 1007=表已存在,1062=主键重复,1050=表重复
SET GLOBAL slave_skip_errors = '1007,1062';
# 永久生效:修改my.cnf,添加slave_skip_errors=1007,1062,重启MySQL根治方案:
对比主从数据,删除从库重复数据(如:
DELETE FROM t1 WHERE id=123;);双主架构需配置主键自增步长分离:sql
# 主库1:自增起始1,步长2(奇数ID)
SET GLOBAL auto_increment_offset = 1;
SET GLOBAL auto_increment_increment = 2;
# 主库2:自增起始2,步长2(偶数ID)
SET GLOBAL auto_increment_offset = 2;
SET GLOBAL auto_increment_increment = 2;
# 永久生效:修改my.cnf,添加上述参数(2)主从版本不一致导致 SQL 不兼容
示例:
主库 MySQL 8.0 执行:
INSERT INTO t1 (name, create_time) VALUES ('xiao', '0000-00-00');(8.0 默认禁止 '0000-00-00' 日期);从库 MySQL 5.6 允许该格式,但若主库开启严格模式,从库未开启,会导致回放失败。处理方案:
尽量保证主从版本一致(推荐主从大版本相同,如均为 8.0.x);
统一主从的 SQL_MODE:sql
# 主从均配置相同的SQL_MODE(示例:兼容模式)
SET GLOBAL sql_mode = 'NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';
# 永久生效:修改my.cnf的sql_mode,重启MySQL避免在高版本主库执行低版本不支持的 SQL(如 8.0 的窗口函数,5.7 以下不支持)。
(3)主从表结构不一致
差异点:字段名、数据类型(如主库 varchar (50),从库 varchar (20))、约束(主键 / 外键)、索引、字段数量现象:Last_SQL_Error 包含 “Unknown column”“Data too long for column”“Foreign key constraint fails” 等处理方案:
对比主从表结构:sql
# 主库导出表结构
mysqldump -uroot -p --no-data 库名 表名 > t1_struct.sql
# 从库导入并对比,或用pt-table-checksum工具校验同步表结构(从库执行):sql
ALTER TABLE 库名.表名 MODIFY COLUMN 字段名 数据类型; # 修正数据类型
ALTER TABLE 库名.表名 ADD PRIMARY KEY (字段名); # 补充主键预防:主库执行 ALTER TABLE 后,立即同步到从库,禁止直接修改从库表结构。
(4)主从延迟引发的 SQL 异常
原因:延迟期间从库被人为写入数据,主库同步的事务与从库本地数据冲突;或延迟过高导致 binlog 被清理。处理方案:
禁止从库写入业务数据(从库设置为 read_only=1,超级管理员仍可操作):sql
SET GLOBAL read_only = 1;
# 永久生效:my.cnf添加read_only=1优化主从延迟:
从库升级硬件(提升 IO/CPU,relay log 和 binlog 放在 SSD);
主库减少大事务(拆分批量 INSERT/UPDATE 为小事务);
关闭从库非必要功能(如 binlog、慢查询日志,仅保留 relay log);
使用并行复制(MySQL 5.7 + 支持):sql
SET GLOBAL slave_parallel_workers = 8; # 并行回放线程数,根据CPU核数调整
# 永久生效:my.cnf添加slave_parallel_workers=8(5)架构设计缺陷导致的异常
场景 1:双主(互为主从)架构数据同步异常
核心问题:未做主键自增步长分离、未过滤系统库同步(如 mysql 库)、双主同时写入相同数据。解决 / 优化:
配置主键自增步长(见上文 “事务回放重复” 部分);
过滤系统库同步(my.cnf 配置):ini
replicate_ignore_db = mysql
replicate_ignore_db = information_schema
replicate_ignore_db = performance_schema双主架构仅保留一个写入节点,另一个作为备用(避免双写)。
场景 2:高可用架构无数据补偿
问题:主库切换后,原主库未同步到新主库的数据丢失,导致从库同步异常。解决:
采用 MGR(MySQL Group Replication)架构,自带数据一致性保障;
高可用切换工具(如 MHA)配置数据补偿脚本,切换前校验主从数据一致性;
定期用 pt-table-checksum 校验主从数据,发现不一致用 pt-table-sync 修复。
4. 数据库克隆方式搭建主从同步(高效数据迁移)
实现克隆数据建立主从同步步骤:
步骤一:准备好主从数据库实例
主库有数据,从干净的库
步骤二:实现克隆迁移部分数据到从库中
主库中做的操作
INSTALL PLUGIN clone SONAME 'mysql_clone.so';
CREATE USER test@'%' IDENTIFIED BY '123456';
GRANT BACKUP_ADMIN, REPLICATION SLAVE ON *.* TO test@'%';
FLUSH PRIVILEGES;
从库中做的操作
INSTALL PLUGIN clone SONAME 'mysql_clone.so';
create user test@'%' identified by '123456';
grant clone_admin on *.* to 'test'@'%';
SET GLOBAL clone_valid_donor_list = '10.0.0.51:3306';
#mysql里克隆命令,下面克隆命令二选一
CLONE INSTANCE FROM test@10.0.0.51:3306 IDENTIFIED BY '123456';
#或者mysql外,命令行克隆命令:
mysql -utest -p123456 -h10.0.0.52 -P3306 -e "clone instance from test@'10.0.0.51':3306 identified by '123456';"
步骤三:完成主从关系建立
基于GTID实现主从同步
change master to master_host='10.0.0.51',master_user='repl',master_password='123456',master_auto_position=1;
start slave;数据库高可用架构MHA
环境准备
MHA搭建部署过程
给 53 主库配置 mha 高可用架构
步骤一:搭建基于事务编号(GTID)的主从同步环境
现在有一台主机,要创建三台主机,53为主库,54、55做从库,56做管理节点,
首先确保三台主机与主库都部署相同版本数据库,且三台主机都是干净的
关闭防火墙并关闭自动启动
先搭建主从GTID
主机54、55、56:(56可以将数据库停止了)
#清除数据
\rm -rf /data/3306/data/* #清除数据目录
mv /etc/my.cnf /tmp #将配置文件
mkdir -p /data/3306/data /data/binlog
chown -R mysql.mysql /data/*
主机53、54、55:
#配置 MySQL GTID(全局事务标识符)
vim /data/3306/my.cnf
[mysqld]
user=mysql
port=3306
datadir=/data/3306/data
basedir=/usr/local/mysql
socket=/tmp/mysql3306.sock
server_id= #根据主机IP修改对应id
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
主机54、55:
#进行数据库初始化操作
mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data
主机53:
systemctl restart mysqld3306.service
mysql -uroot -S /tmp/mysql3306.sock
#随便增删改查,为了创建GTID(我这里就创建linshi库了)
mysql> create database linshi;
mysql> show master status;
+---------------+----------+--------------+------------------+----------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+----------------------------------------+
| binlog.000003 | 348 | | | 04f91d25-e601-11f0-a0ed-000c2970bc9c:1 |
+---------------+----------+--------------+------------------+----------------------------------------+
1 row in set (0.00 sec)
#逻辑备份,将数据同步给从库54、55
mysqldump -uroot -S /tmp/mysql3306.sock -A --single-transaction --source-data=2 --routines --triggers > /backup/all.sql
scp -rp /backup/all.sql root@10.0.0.54:/backup/
主机54、55:
[root@db54 ~]# ll /backup/
-rw-r--r--. 1 root root 1285354 12月 31 19:48 all.sql
systemctl start mysqld3306.service
systemctl status mysqld3306.service #检查是否启动
mysql -uroot -S /tmp/mysql3306.sock </backup/all.sql
mysql -uroot -S /tmp/mysql3306.sock
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| linshi | #可以看到数据已经同步到从库
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.01 sec)
主机53:主库-数据库中设置主从用户
登录数据库:mysql -uroot -S /tmp/mysql3306.sock
create user repl@'10.0.0.%' identified with mysql_native_password by '123456';
grant replication slave on *.* to repl@'10.0.0.%';
主机54、55:从库中做主从功能配置
CHANGE MASTER TO
MASTER_HOST='10.0.0.53',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='123456',
master_auto_position=1,
MASTER_CONNECT_RETRY=10;
#启动主从同步功能
start slave;
#查看同步状态:
SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#验证(主库删除linshi库,看从库是否同步删除)
主库53:
mysql> drop database linshi;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
从库54、55:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
---以上操作实际上就是搭建基于事务编号(GTID)的主从同步-----------------------------------------------------------------------
步骤二:搭建MHA高可用架构
环境准备完成,开始搭建MHA高可用架构
主机53:创建密钥,分发给从节点,实现主从节点互相连接通信
将主机53、54、55密钥备份:mv /root/.ssh /root/.ssh.bak
ssh-keygen
cd /root/.ssh/
mv id_rsa.pub authorized_keys
scp -r /root/.ssh root@10.0.0.55:/~
主机53、54、55、56:
yum install perl-DBD-MySQL -y
#上传mha软件包,软件包所需内容:
mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
mha4mysql-node-0.58-0.el7.centos.noarch.rpm
unzip mha.zip -d /usr/local/
cd /usr/local/
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
#验证
[root@db53 local]# rpm -qa|grep mha
mha4mysql-node-0.58-0.el7.centos.noarch
主机56(管理节点):
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
#编写mha配置文件
mkdir -p /etc/mha #创建配置文件目录
mkdir -p /var/log/mha/app1 #创建日志目录
主机53、54、55:创建mha需要的用户(只需要在主库53创建就可,会自动同步到从库)
create user mha@'10.0.0.%' identified with mysql_native_password by 'mha';
grant all privileges on *.* to mha@'10.0.0.%';
主机56:编写配置文件(记得要把注释去掉)
cat > /etc/mha/app1.cnf <<EOF
[server default]
manager_log=/var/log/mha/app1/manager #MHA日志文件manager存放位置
manager_workdir=/var/log/mha/app1 #MHA的工作目录
master_binlog_dir=/data/3306/data/ #主库的binlog目录(实现mha数据补偿功能)
user=mha #监控用户,利用此用户连接各个节点,做心跳检测(主要是检测主库的状态)
password=mha #监控密码
ping_interval=2 #心跳检测的间隔时间
repl_password=123456 #复制密码
repl_user=repl #复制用户(用于告知从节点通过新主同步数据信息的用户信息)
ssh_user=root #ssh互信的用户(可以利用互信用户从主库scp获取binlog日志信息,便于从库进行数据信息补偿)
[server1]
hostname=10.0.0.53
port=3306
[server2]
hostname=10.0.0.54
port=3306
[server3]
hostname=10.0.0.55
port=3306
#candidate_master=1
EOF
#启动mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
参数说明:
--conf=/etc/mha/app1.cnf -- 加载mha配置文件信息
--remove_dead_master_conf -- 将故障主节点配置信息从配置文件中删除,避免影响到后续选主过程
--ignore_last_failover -- 忽略错误日志信息,可以重新恢复启动mha服务程序
< /dev/null -- 忽略脚本或代码信息的交互过程
#检查mha进程
ps -ef |grep mha
#检查主从同步
masterha_check_repl --conf=/etc/mha/app1.cnf
#检查ssh互信
masterha_check_ssh --conf=/etc/mha/app1.cnf
[root@db56 local]# ps -ef |grep mha
root 2667 1633 0 21:36 pts/0 00:00:00 perl /usr/bin/masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover
步骤三:高可用额外配置
主机56:
#软件包
[root@db56 mha_script]# ll
总用量 28
-rw-r--r--. 1 root root 2230 10月 10 2022 master_ip_failover
-rw-r--r--. 1 root root 10312 10月 10 2022 master_ip_online_change
-rw-r--r--. 1 root root 789 10月 10 2022 mha_check.sh
-rw-r--r--. 1 root root 2238 10月 10 2022 send_report
[root@db56 mha_script]# mv ./* /usr/local/bin/
[root@db56 mha_script]# cd /usr/local/bin/
[root@db56 bin]# chmod +x ./*
[root@db56 bin]# ll
总用量 24
-rwxr-xr-x. 1 root root 2230 10月 10 2022 master_ip_failover
-rwxr-xr-x. 1 root root 10312 10月 10 2022 master_ip_online_change
-rwxr-xr-x. 1 root root 789 10月 10 2022 mha_check.sh
-rwxr-xr-x. 1 root root 2238 10月 10 2022 send_report
cp master_ip_failover{,.bak}
vim master_ip_failover
13 my $vip = '10.0.0.50/24'; #vip地址信息
14 my $key = '1'; #网卡别名
15 my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; #当主节点挂了,在从节点新生成VIP地址
16 my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; #将原主库VIP地址清除,避免脑裂
17 my $ssh_Bcast_arp= "/sbin/arping -I ens33 -c 3 -A 10.0.0.50"; #漂移到新主节点,可以使前端正常访问
主机53:第一次设置VIP漂移,需要在主库手动执行
yum -y install net-tools
/sbin/ifconfig ens33:1 10.0.0.50/24
主机56:
#修改配置文件,自动执行脚本
[root@db56 ~]# vim /etc/mha/app1.cnf
master_ip_failover_script=/usr/local/bin/master_ip_failover
----创建MHA故障报警通知功能---------------------------------
主机56:
vim send_report
28 my $smtp='smtp.163.com';
29 my $mail_from='fanxuxu666@163.com';
30 my $mail_user='fanxuxu666@163.com';
31 my $mail_pass='RJuxjmwN9YC9V7Uy';
32 #my $mail_to=['to1@qq.com','to2@qq.com']; #如果发多个人
33 my $mail_to='549202119@qq.com'; #如果只发自己
# 修改配置文件
[root@db56 ~]# vim /etc/mha/app1.cnf
report_script=/usr/local/bin/send_report
# 重启MHA服务
[root@db56]# masterha_stop --conf=/etc/mha/app1.cnf
[root@db56]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
----创建MHA额外补偿功能---------------------------------
#利用binlog_server作为额外的日志补偿的冗余方案,即实时保存主库的bin_log日志文件到特定节点目录中
主机56:
#创建日志存放目录
mkdir -p /data/binlog_server/
chown -R mysql.mysql /data/*
cd /data/binlog_server
主机53:在主库读取现在binlog信息
[root@db53 binlog_server]# mysql -uroot -S /tmp/mysql3306.sock -e "show binary logs\G"|grep "binlog"
Log_name: binlog.000001
Log_name: binlog.000002
Log_name: binlog.000003
主机56:
mysqlbinlog -R --host=10.0.0.53 --user=mha --password=mha --raw --stop-never binlog.000001 &
[root@db56 binlog_server]# ll
总用量 12
-rw-r-----. 1 root root 201 12月 31 22:44 binlog.000001
-rw-r-----. 1 root root 180 12月 31 22:44 binlog.000002
-rw-r-----. 1 root root 1564 12月 31 22:44 binlog.000003
# 编写配置文件信息
[root@db56 ~]# vim /etc/mha/app1.cnf
[binlog1]
no_master=1 #不参与竞选
hostname=10.0.0.56 #将日志额外补偿到哪个主机上
master_binlog_dir=/data/binlog_server/ #日志额外补偿的存储目录
# 重启MHA服务
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
[root@db56 ]# ps -ef |grep mha
root 5455 4687 0 22:44 pts/1 00:00:00 mysqlbinlog -R --host=10.0.0.53 --user=mh --password=x x --raw --stop-never binlog.000001
root 5646 4687 6 22:51 pts/1 00:00:00 perl /usr/bin/masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover
#检查mha状态
[root@db56 ]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:5646) is running(0:PING_OK), master:10.0.0.53
步骤四:测试高可用
主机53、54、55、56:在所有节点创建软连接信息
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
#模拟主数据库出现故障停止
/etc/init.d/mysqld stop
当主库出现故障后,会触发高可用故障转移功能
1)实现VIP地址漂移 (主库vip消失 新的主库出现VIP)
2)主从关系会重新构建 52主库 52 53从 ---> 52主库 53从
3)在mha配置文件中 会清除51主库节点信息的配置
4)查看邮件信息,是否收到报警邮件
5)在MHA管理节点上,查看mha服务状态变为关闭状态
--------------------------------------------------------------
主库53节点:
systemctl stop mysqld3306.service
54节点:可以看到VIP漂移到54节点了
[root@db54 ~]# ip a
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:7d:5c:c1 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.54/24 brd 10.0.0.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 10.0.0.50/24 brd 10.0.0.255 scope global secondary ens33:1
#进入数据库查看从节点信息,查看不到了,因为它现在不是从节点了
mysql> SHOW SLAVE STATUS\G
Empty set, 1 warning (0.00 sec)
56节点:查看配置文件,[server1]被自动清理
[root@db56 ~]# cat /etc/mha/app1.cnf
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/3306/data/
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=mha
ping_interval=2
repl_password=123456
repl_user=repl
report_script=/usr/local/bin/send_report
ssh_user=root
user=mha
[server2]
hostname=10.0.0.54
port=3306
[server3]
hostname=10.0.0.55
port=3306
#检查状态:主库挂了之前,检查状态是OK的,主库挂了之后会显示NOT_RUNNING
[root@db56 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:5646) is running(0:PING_OK), master:10.0.0.53
[root@db56 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
除了没有收到邮件,其它都有。步骤五:恢复主库/手动切换主库
主机53:
确认主库53VIP是否消失,确认从库有VIP
恢复主库(排查故障并恢复、复盘)
systemctl start mysqld3306
#重新构建主从关系
change master to master_host='10.0.0.54',master_user='repl',master_password='123456',master_auto_position=1;
start slave;
PS:确保主从数据基本一致 Seconds_Behind_Master: 0 没有数据的同步差异
主机56:
#重新添加53节点
vim /etc/mha/app1.cnf
[server1]
hostname=10.0.0.53
port=3306
#重新恢复mha,就要同步新的主机点
cd /data/binlog_server/
\rm -rf ./*
mysqlbinlog -R --host=10.0.0.54 --user=mha --password=mha --raw --stop-never binlog.000001 &
主机54:
确认新的主库54节点VIP地址是否存在,原有主库VIP地址是否消失
/sbin/ifconfig ens33:1 10.0.0.50/24
主机56:
重启启动恢复mha服务程序
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
masterha_check_status --conf=/etc/mha/app1.cnf
-----------------------------------------------------------------------
流量低谷期恢复主机53,将53重新设为主库
数据库高可用架构-手动故障转移
手动故障转移切换目的:
- 可以恢复原有主库的功能
- 出现维护性工作时,需要进行手工切换
步骤一:确认主从数据是否一致
步骤二:暂时停止主库写入功能
步骤三:关闭管理节点MHA监控功能
masterha_stop --conf=/etc/mha/app1.cnf
masterha_check_status --conf=/etc/mha/app1.cnf
步骤四:利用脚本实现手工切换主备角色(管理节点)
vim /usr/local/bin/master_ip_online_change
21 my $vip = "10.0.0.50/24";
22 my $key = "1";
23 my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
24 my $ssh_stop_vip = "/sbin/ifconfig ens33:$key $vip down";
25 my $ssh_Bcast_arp= "/sbin/arping -I ens33 -c 3 -A 10.0.0.50/24";
vim /etc/mha/app1.cnf
[server default]
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=10.0.0.51 --orig_master_is_new_slave --running_updates_limit=10000
说明:
--master_state=alive -- 在主库节点运行状态,实现高可用切换
--new_master_host=10.0.0.53 -- 指定哪个从节点接替主库的角色身份
--orig_master_is_new_slave -- 让其他从节点可以重新和新的主节点建立主从关系
--running_updates_limit=10000 -- 在手工切换指定时间内,无法完成顺利切换,会停止切换过程
Switching master to 10.0.0.51(10.0.0.51:3306) completed successfully.
#开启mha补偿(binlog同步)
cd /data/binlog_server/
mysqlbinlog -R --host=10.0.0.53 --user=mha --password=mha --raw --stop-never binlog.000001 &
#启动mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
masterha_check_status --conf=/etc/mha/app1.cnf
步骤五:主从切换后验证过程
vip 地址 主从关系 binlog远程备份
步骤六:创建读写分离
Proxysql 下载:https://proxysql.com/documentation/installing-proxysql/
步骤一:在中间件服务节点上安装proxySQL软件程序
将安装包上传到系统proxysql-2.4.6-1-centos7.x86_64
rpm -ivh proxysql-2.4.6-1-centos7.x86_64.rpm
步骤二:启动运行软件程序
systemctl start proxysql #启动proxysql服务
#查看端口
ss -lntup|grep proxysql
tcp LISTEN 0 128 *:6032 *:* users:(("proxysql",pid=10700,fd=42))
tcp LISTEN 0 128 *:6033 *:* users:(("proxysql",pid=10700,fd=34))
说明:
6032 -- proxySQL管理端口 利用此端口连接proxysql,可以对服务进行管理配置
6033 -- proxySQL访问端口 利用此端口连接proxysql,可以实现读写分离效果
步骤三:对proxySQL服务进行读写分离配置
mysql -uadmin -padmin -h127.0.0.1 -P6032
-- 连接登录proxySQL后,可以对proxySQL中的表做设置,实现读写分离功能设置
表01 -- mysql_replication_hostgroup (insert update delete)
-- 创建读写分离功能组信息 (10-写组-10.0.0.53 20-读组-10.0.0.54 10.0.0.55 10.0.0.56)
表02 -- mysql_servers
-- 定义读写分离节点信息,并划分到对应组中 53 54 55 56
表03 -- global_variables
-- 创建监控用户信息,后端节点健康检查
表04 -- mysql_users
-- 创建业务用户信息,用于处理前端业务访问,并利用此用户连接后端
wordpress -- blog -- blog用户
bbs -- bbs -- bbs用户
表05 -- mysql_query_rules 识别SQL语句-读请求语句(select/show)-- 分给20号读组 -- 负载均衡给 51--53
-- 利用规则表可以实现读写分离效果 识别SQL语句-写请求语句(select/show)-- 分给10号写组 -- 负载均衡给 51-vip50
步骤四:测试读写分离效果
表01 -- mysql_replication_hostgroups (insert update delete)
-- 创建读写分离功能组信息 (10-写组-10.0.0.53 20-读组-10.0.0.54 10.0.0.55 10.0.0.56)
主机54、55:在从库上设置只读配置项:
set global read_only=1; -- 10.0.0.54
set global read_only=1; -- 10.0.0.55
主机56:
insert into mysql_replication_hostgroups(writer_hostgroup,reader_hostgroup,comment) values(10,20,'proxy');
load mysql servers to runtime; #计划配置 --加载到-- runtime_mysql_replication_hostgroups 使配置立即生效
save mysql servers to disk; #将配置信息保存到磁盘中
表02 -- mysql_servers
-- 定义读写分离节点信息,并划分到对应组中 53 54 55 56
insert into mysql_servers(hostgroup_id,hostname,port) values (10,'10.0.0.53',3306);
insert into mysql_servers(hostgroup_id,hostname,port) values (20,'10.0.0.54',3306);
insert into mysql_servers(hostgroup_id,hostname,port) values (20,'10.0.0.55',3306);
#保存
load mysql servers to runtime; #mysql_servers -load-> runtime_mysql_servers
save mysql servers to disk; #将配置信息保存到磁盘中
#查询
select * from mysql_servers\G;
表03 -- global_variables
主机56:查询(此表默认信息)
select * from global_variables;
| mysql-monitor_username | monitor |
| mysql-monitor_password | monitor |
主机53(主库):创建用户monitor
create user monitor@'%' identified with mysql_native_password by '123';
grant replication client on *.* to monitor@'%';
主机56:在proxysql中修改variables表配置信息
set mysql-monitor_username='monitor';
set mysql-monitor_password='123';
或
update global_variables set variable_value='monitor' where variable_name='mysql-monitor_username';
update global_variables set variable_value='123' where variable_name='mysql-monitor_password';
-- 以上变量信息修改方法二选一
#保存配置
load mysql variables to runtime;
save mysql variables to disk;
# 检查核实配置信息
select @@mysql-monitor_username;
select @@mysql-monitor_password;
表04 -- mysql_users
主机53(主库):
#创建业务用户信息,用于处理前端业务访问,并利用此用户连接后端
create user root@'%' identified with mysql_native_password by '123';
grant all on *.* to root@'%';
主机56:管理节点
# 在proxysql中添加数据库节点的管理用户信息
insert into mysql_users(username,password,default_hostgroup) values('root','123',10);
load mysql users to runtime;
save mysql users to disk;
其它说明:
web服务 -- 中间件 --- 主节点/从节点
root 123 mysql_users(root 123) --- root 123
成功建立连接
SQL语句请求 SQL语句请求
www 123 www 123 10/20 --- 主节点/从节点 51 /52 53
grant all www on www.* www 123
bbs 456 bbs 456 30/40 --- 主节点/从节点 61 /62 63
grant all bbs on bbs.* bbs 456
game 789 game 789 50/60 --- 主节点/从节点 71 /72 73
grant all game on game.* game 789
表05 -- mysql_query_rules(利用规则表可以实现读写分离效果)
#识别SQL语句-读请求语句(select/show)-- 分给20号读组 -- 负载均衡给 54--56
#识别SQL语句-写请求语句(select/show)-- 分给10号写组 -- 负载均衡给 53(vip50)
主机56:管理节点配置
insert into mysql_query_rules(rule_id,active,match_pattern,destination_hostgroup,apply) values (1,1,'^select.*for update$',10,1);
insert into mysql_query_rules(rule_id,active,match_pattern,destination_hostgroup,apply) values (2,1,'^select',20,1);
INSERT INTO mysql_query_rules (rule_id,active,match_pattern,destination_hostgroup,apply,comment) VALUES (3, 1, '^(INSERT|UPDATE|DELETE|REPLACE|CREATE|ALTER|DROP|TRUNCATE)',10,1,'写操作:DML/DDL路由到主库53');
#以上规则策略都不匹配时,会自动将请求发送到写组
load mysql query rules to runtime;
save mysql query rules to disk;
步骤四:测试读写分离效果
任意选择一个有数据库程序节点,连接访问中间件服务(6033)
#模拟测试写操作,是否只转发给主节点
mysql -uroot -p123 -h10.0.0.56 -P6033 -e "begin;select @@server_id;commit;"
[root@db53 ~]# mysql -uroot -p123 -h10.0.0.56 -P6033 -e "begin;select @@server_id;commit;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+-------------+
| @@server_id |
+-------------+
| 53 |
+-------------+
[root@db53 ~]# mysql -uroot -p123 -h10.0.0.56 -P6033 -e "begin;select @@server_id;commit;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+-------------+
| @@server_id |
+-------------+
| 53 |
+-------------+
任意节点:
#模拟测试读操作,是否实现读请求负载均衡
mysql -uroot -p123 -h10.0.0.56 -P6033 -e "select @@server_id;commit;"
[root@db53 ~]# mysql -uroot -p123 -h10.0.0.56 -P6033 -e "select @@server_id;commit;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+-------------+
| @@server_id |
+-------------+
| 53 |
+-------------+
[root@db53 ~]# mysql -uroot -p123 -h10.0.0.56 -P6033 -e "select @@server_id;commit;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+-------------+
| @@server_id |
+-------------+
| 54 |
+-------------+
[root@db53 ~]# mysql -uroot -p123 -h10.0.0.56 -P6033 -e "select @@server_id;commit;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+-------------+
| @@server_id |
+-------------+
| 55 |
+-------------+
[root@db53 ~]# mysql -uroot -p123 -h10.0.0.56 -P6033 -e "select @@server_id;commit;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+-------------+
| @@server_id |
+-------------+
| 55 |
+-------------+
非关系数据库服务应用-redis
Redis介绍
Redis(Remote Dictionary Server,远程字典服务器)是一款开源的、高性能的键值对(Key-Value)内存数据库,由 Salvatore Sanfilippo 开发,基于 ANSI C 编写,遵循 BSD 协议。它突破了传统关系型数据库的磁盘 IO 瓶颈,核心数据默认存储在内存中,同时支持数据持久化到磁盘,兼具「高速读写」和「数据持久化」特性;此外,Redis 还支持丰富的数据结构、集群、事务、发布订阅等功能,是目前互联网领域最主流的中间件之一。
Redis 核心特性
内存优先 + 持久化:数据默认存内存,读写速度极快(单机 QPS 可达 10 万 +);支持 RDB(快照)、AOF(日志)两种持久化方式,避免内存数据丢失。
丰富的数据结构:不仅支持字符串(String),还提供哈希(Hash)、列表(List)、集合(Set)、有序集合(ZSet)、位图(Bitmap)、地理空间(GEO)、流(Stream)等结构化数据类型。
高可用与分布式:支持主从复制、哨兵(Sentinel)、集群(Cluster)模式,满足高可用、高并发、水平扩展需求。
原子操作 + 事务:所有单命令都是原子性的,支持简单事务(MULTI/EXEC)、Lua 脚本,保证业务逻辑的一致性。
多功能扩展:内置发布订阅、过期策略、缓存淘汰、管道(Pipeline)、HyperLogLog(基数统计)等功能。
Redis 核心作用
1. 缓存(最核心场景)
作用:将数据库的热点数据(如商品详情、用户信息、首页数据)缓存到 Redis,减少数据库(MySQL/Oracle)的读写压力,提升接口响应速度。
典型用法:
缓存用户登录态(Token)、商品库存、热点资讯;
结合过期时间(EXPIRE)实现缓存自动失效;
配置缓存淘汰策略(如 LRU)避免内存溢出。
2. 分布式锁
作用:解决分布式系统中「并发资源竞争」问题(如秒杀、库存扣减、订单创建)。
典型用法:
用
SETNX(SET if Not Exists)实现锁的抢占;结合
EXPIRE设置锁超时,避免死锁;推荐用
Redlock算法实现分布式锁的高可用。
3. 计数器 / 限流器
作用:利用 Redis 的原子自增(INCR/DECR)特性,实现高性能计数、限流。
典型用法:
文章阅读量、视频播放量、点赞数实时计数;
接口限流(如单 IP 每分钟最多访问 100 次);
秒杀活动中的库存实时扣减。
4. 消息队列(轻量级)
作用:替代部分 MQ(如 RabbitMQ/Kafka),实现简单的消息生产消费。
典型用法:
用 List 的 LPUSH/RPOP 实现简单队列;
用 Stream 实现持久化、多消费者的消息队列(类似 Kafka);
发布订阅(PUB/SUB)实现消息广播(如实时通知)。
5. 会话存储
作用:分布式系统中,将用户会话(Session)统一存储到 Redis,替代单机 Session,实现会话共享。
典型用法:
登录态存储(如电商系统的用户登录信息);
避免分布式部署时「登录态只在某台机器生效」的问题。
6. 数据去重 / 统计
作用:利用 Set(无序、唯一)、ZSet(有序)、HyperLogLog 实现数据去重和统计。
典型用法:
Set 存储用户标签、点赞用户列表(自动去重);
ZSet 实现排行榜(如商品销量榜、用户积分榜);
HyperLogLog 统计网站 UV(海量数据下的基数估算,误差约 1%)。
7. 地理空间服务
作用:基于 GEO 数据结构实现 LBS(位置服务)。
典型用法:
附近的人、附近的商家(GEOADD/GEOSEARCH);
打车软件的司机位置匹配、外卖配送范围判断。
Redis 常见问题 / 注意事项(运维 / 开发高频点)
1. 缓存相关问题
缓存穿透:请求不存在的 Key,导致每次都穿透到数据库。解决方案:缓存空值、布隆过滤器。
缓存击穿:热点 Key 过期瞬间,大量请求打向数据库。解决方案:热点 Key 永不过期、互斥锁、分布式锁。
缓存雪崩:大量 Key 同时过期,或 Redis 宕机,导致数据库压力骤增。解决方案:过期时间加随机值、Redis 集群 / 哨兵、降级限流。
2. 持久化相关问题
RDB vs AOF:
RDB:性能高、文件小,但可能丢失最近的数据;适合做全量备份。
AOF:数据安全性高(可配置每秒 / 每次命令刷盘),但文件大、恢复慢;适合做增量持久化。
生产建议:开启混合持久化(RDB+AOF),兼顾性能和安全性。
3. 高可用相关问题
主从复制:主库写、从库读,提升读性能;但主库宕机后需手动切换。
哨兵(Sentinel):自动监控主从状态,主库宕机时自动切换到从库,实现高可用。
集群(Cluster):分片存储数据,支持水平扩展(最多 16384 个分片),解决单机内存瓶颈。
4. 性能优化
避免大 Key(如超大 String、百万级 List):大 Key 会导致内存碎片、删除阻塞、网络传输慢。
合理使用管道(Pipeline):将多个命令批量发送,减少网络往返次数。
禁用慢查询:避免执行
KEYS *、HGETALL等耗时命令,用SCAN替代。配置合理的内存策略:如
maxmemory-policy allkeys-lru(内存满时淘汰最少使用的 Key)。
5. 数据一致性
缓存与数据库的一致性:推荐「先更数据库,再删缓存」(避免并发下的脏数据),或用 Canal 监听数据库 binlog 同步缓存。
Redis 与其他中间件的对比
Redis安装
#官⽅命令参考
# 官⽅各版本的下载地址
https://redis.io/download/#redis-downloads
https://download.redis.io/releases
# 0.安装依赖(依赖高版本gcc)
红帽:yum install -y gcc gcc-c++ automake autoconf libtool make tcl libssl-devel glibc-devel libatomic
Debian:apt install -y gcc g++ automake autoconf libtool make tcl8.6 libssl-dev libc6-dev libatomic1
# 1. 下载Redis 8.0源码
wget https://download.redis.io/releases/redis-8.0.0.tar.gz
tar -zxvf redis-8.0.0.tar.gz -C /usr/local
cd /usr/local/redis-8.0.0/
# 2. 编译
make distclean # 清空旧编译缓存
make BUILD_TLS=yes -j $(nproc) # 多核编译,开启TLS
# 3. 环境变量
echo 'export PATH="/usr/local/redis-8.0.0/src:$PATH"' >> /etc/profile
source /etc/profile
# 3. 检查
redis-server --version # 输出Redis 8.0.0则正常
# 5. 运行官方测试用例(验证依赖)
make test
#测试后,有3个测试用例失败(其余[ignore]是正常跳过),这些失败均属于「特定功能的兼容性 / 资源限制问题」
#不影响 Redis 核心功能(缓存、分布式锁、集群等)的生产使用
# 6. 后期优化
#生产环境关键配置建议
编辑redis.conf
active-defrag no # 禁用主动碎片整理(生产默认关闭)
repl-timeout 60 # 延长复制超时时间(默认60秒,足够应对大部分场景)
repl-backlog-size 1gb # 增大复制积压缓冲区(避免从库重连全量同步)
echo "vm.overcommit_memory=1" >> /etc/sysctl.conf
echo "vm.swappiness=0" >> /etc/sysctl.conf
sysctl -p安装依赖:
红帽:yum install -y gcc gcc-c++ automake autoconf libtool make tcl libssl-devel glibc-devel libatomic
Debian:apt install -y gcc g++ automake autoconf libtool make tcl8.6 libssl-dev libc6-dev libatomic1
安装部署 Redis:
wget https://download.redis.io/releases/redis-6.2.12.tar.gz
tar xf redis-6.2.12.tar.gz -C /usr/local/
cd /usr/local/
ln -s redis-6.2.12 redis
cd redis
make && make install
vim /etc/profile
export PATH="/usr/local/redis/src:$PATH"
source /etc/profile
启动 redis
redis-server &
Redis 服务登录操作:
redis-cli
Redis
理
#创建目录
mkdir -
登录白名单
vim /data/6379/redis.conf
bind 10.0.0.53 127.0.0.1
#重启
redis-cli shutdown
redis-server /data/6379/redis.conf
#远程连接
[root@db53 ~]# redis-cli -h 10.0.0.53
10.0.0.53:6379> set name fanxuxu
OK
10.0.0.53:6379> get name
"fanxuxu"
#添加认证密码
vim /data/6379/redis.conf
requirepass 123456
[root@db53 ~]# redis-cli -h 10.0.0.53
10.0.0.53:6379> get name
(error) NOAUTH Authentication required.
10.0.0.53:6379> auth 123456 #密码认证后才有权限操作
OK
10.0.0.53:6379> get name
"fanxuxu"Redis多实例配置
# 编写生成主从缓存服务配置文件
mkdir -p /data/638{0..2}
cat >>/data/6380/redis.conf <<EOF
port 6380
daemonize yes
pidfile /data/6380/redis.pid
loglevel notice
logfile "/data/6380/redis.log"
dbfilename dump.rdb
dir /data/6380
requirepass 123456
masterauth 123456
EOF
-- 缓存服务主库配置文件编写
cat >>/data/6381/redis.conf <<EOF
port 6381
daemonize yes
pidfile /data/6381/redis.pid
loglevel notice
logfile "/data/6381/redis.log"
dbfilename dump.rdb
dir /data/6381
requirepass 123456
masterauth 123456
EOF
cat >>/data/6382/redis.conf <<EOF
port 6382
daemonize yes
pidfile /data/6382/redis.pid
loglevel notice
logfile "/data/6382/redis.log"
dbfilename dump.rdb
dir /data/6382
requirepass 123456
masterauth 123456
EOF
-- 缓存服务从库配置文件编写
#启动redis
redis-server /data/6380/redis.conf
redis-server /data/6381/redis.conf
redis-server /data/6382/redis.conf
#查看端口
netstat -lntup|grep redis
tcp 0 0 0.0.0.0:6380 0.0.0.0:* LISTEN 27453/redis-server
tcp 0 0 0.0.0.0:6381 0.0.0.0:* LISTEN 27459/redis-server
tcp 0 0 0.0.0.0:6382 0.0.0.0:* LISTEN 27465/redis-server
-- 显示的端口信息中:6380为主节点缓存服务,6381/6382位从节点缓存服务;Redis主从同步架构
redis主从同步基本原理
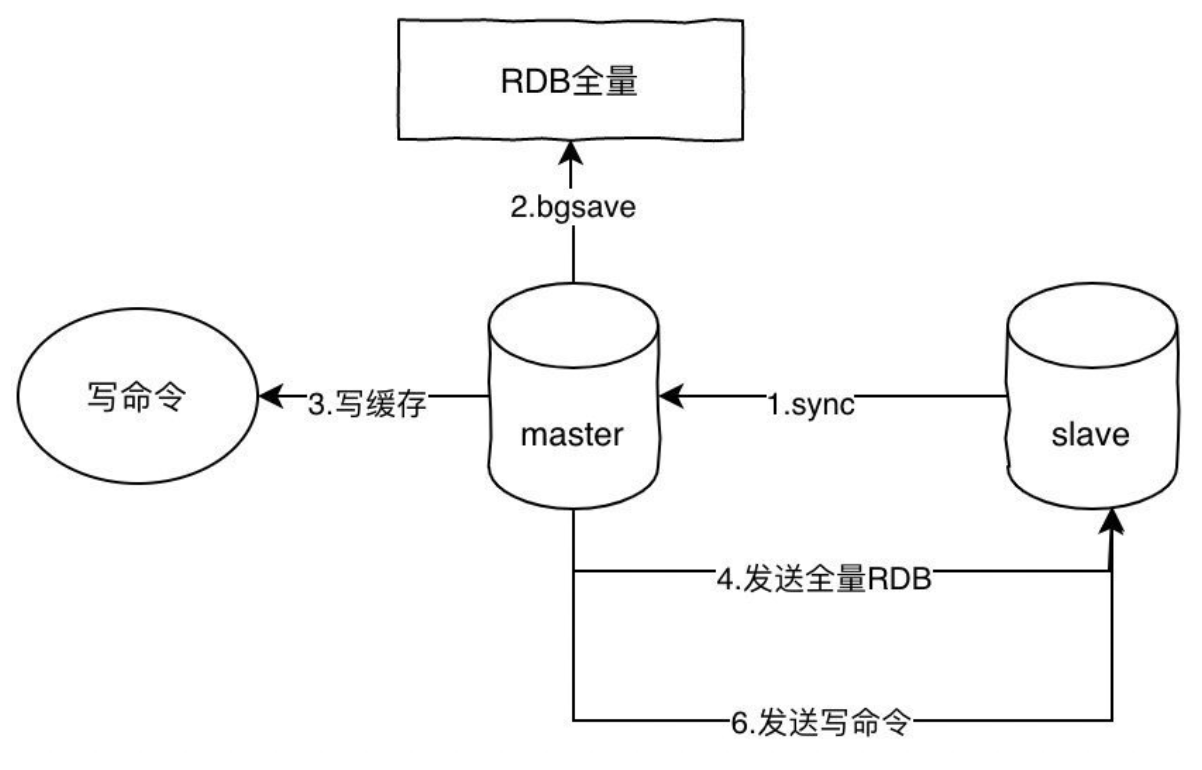
redis主从同步配置
我就在同一台主机创建多实例来演示配置主从
# redis从库开启主从同步
redis-cli -p 6381 -a 123456 slaveof 127.0.0.1 6380
redis-cli -p 6382 -a 123456 slaveof 127.0.0.1 6380
# 进行主从同步状态查看
[root@db53 ~]# redis-cli -p 6380 -a 123456 info replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=126,lag=0
slave1:ip=127.0.0.1,port=6382,state=online,offset=126,lag=0
# 解除主从同步关系状态
[root@master ~]# redis-cli -p 6382 -a 123456 slaveof no one
或者
[root@master ~]# redis-cli -p 6382 -a 123456 replicaof no one
Redis高可用架构-哨兵模式
# 编写哨兵实例服务配置信息:
mkdir /data/26380
[root@db53 ]# vim /data/26380/sentinel.conf
port 26380
dir "/data/26380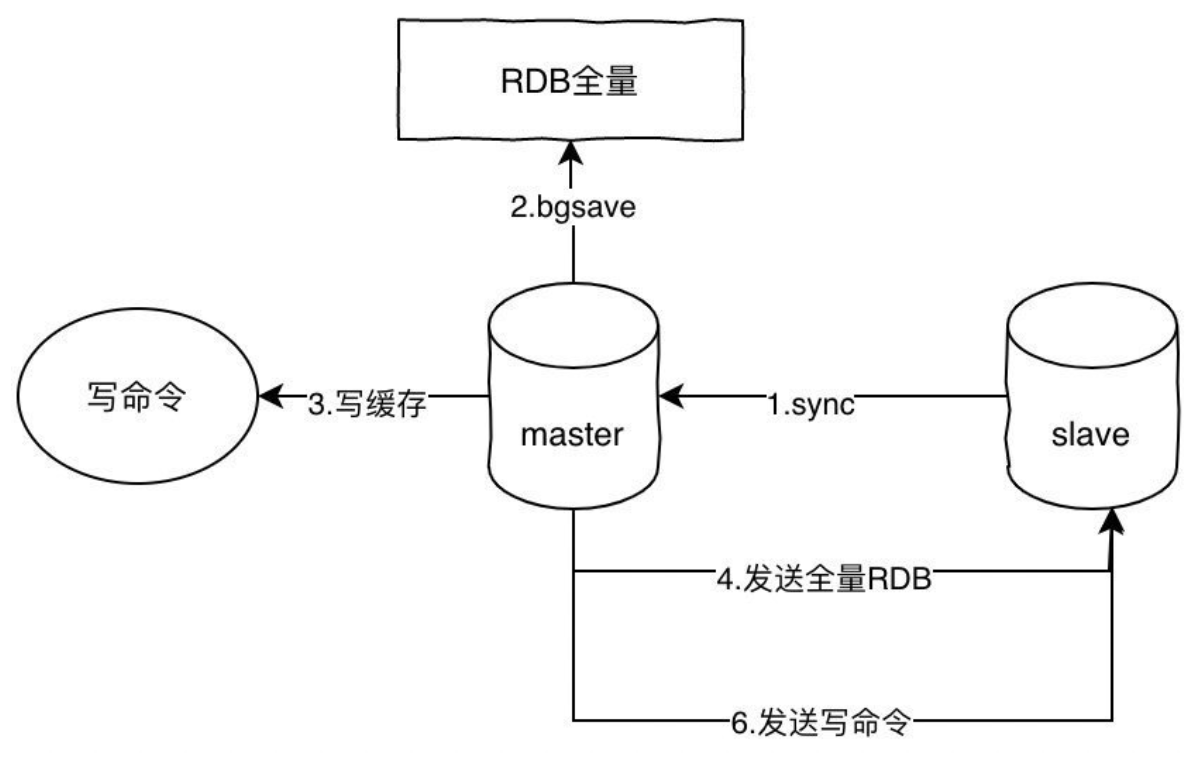
s
#查看指定架构集群从库节点状态信息
127.0.0.1:26380> SENTINEL slaves mymaster
#查看获取主库节点的地址和端口信息
127.0.0.1:26380> SENTINEL get-master-addr-by-name mymaster
------------------------分隔符----------------------------------------------
场景案例:
主库故障转移后,想让哨兵重新 “认” 主库;
哨兵误判主库宕机(假故障),需清除错误状态;
修改了主库配置(如端口、密码),需让哨兵重新探测。
#重置所有名称匹配 <pattern> 通配符的主库的哨兵状态:包括清空该主库的故障记录、重置投票状态、重新发现从库 / 其他哨兵、恢复对主库的监控。
命令:SENTINEL reset <pattern>
#执行后,哨兵会:
① 停止对该主库的现有监控;
② 重新连接主库,获取最新的从库列表;
③ 与集群中其他哨兵重新握手,同步状态。
举例1:重置单个主库(mymaster)
# 进入哨兵客户端(26380端口)
redis-cli -p 26380
# 重置名称为mymaster的主库(pattern直接写主库名,精确匹配)
127.0.0.1:26380> SENTINEL reset mymaster
(integer) 1 # 返回1表示成功重置1个主库
举例 2:重置所有主库(通配符 *)
# 重置哨兵监控的所有主库(适合多主库场景)
127.0.0.1:26380> SENTINEL reset *
(integer) 2 # 返回2表示成功重置2个主库(假设监控了mymaster、mymaster2)
举例 3:重置以 “my” 开头的主库(通配符 my*)
127.0.0.1:26380> SENTINEL reset my*
(integer) 1 # 匹配mymaster,重置1个
#验证重置效果:重置后,查看主库状态,确认哨兵已重新探测
127.0.0.1:26380> SENTINEL masters
# 输出中会看到mymaster的状态更新(如last_ok_ping时间变为最新)
------------------------分隔符----------------------------------------------
命令:SENTINEL failover <master name>
说明:<master name>:哨兵配置中定义的主库名称(如 mymaster),必须精确匹配。
作用:手动强制触发指定主库的故障转移(无需等待哨兵检测到主库宕机),核心逻辑:
① 哨兵集群协商选出最优从库;
② 将该从库升级为新主库;
③ 其他从库重新指向新主库;
④ 原主库恢复后,会自动变为新主库的从库。
应用场景:
主库需要停机维护(如升级、重启),提前手动切换,避免业务中断;
哨兵自动故障转移未触发(如网络抖动导致哨兵未检测到故障),手动兜底;
测试哨兵故障转移逻辑是否正常。
举例:手动触发故障转移(当主服务器失效时,在不询问其他sentinel意见的情况下,强制开始一次自动故障迁移;)
#在哨兵实例中查看当前主库是谁?
127.0.0.1:26380> SENTINEL get-master-addr-by-name mymaster
1) "127.0.0.1"
2) "6382"
#手动切换主库
127.0.0.1:26380> SENTINEL failover mymaster
#再次查看主库地址
127.0.0.1:26380> SENTINEL get-master-addr-by-name mymaster
1) "127.0.0.1"
2) "6380"
Redis集群架构-分布式存储
我创建多实例来部署分布式存储举例
集群架构环境插件安装:
当 Redis <5.0 时,需要依赖集群构建的插件
当 Redis ≥5.0 时,Redis 内置的 redis-cli 原生集群命令
# epel源安装ruby支持,并使用国内源下载插件(Redis ≥5.0无需安装)
yum install ruby rubygems -y
gem sources -l
gem sources -a http://mirrors.aliyun.com/rubygems/
gem sources --remove http://rubygems.org/
gem sources -l
gem install redis -v 3.3.3 #假设你安装的版本为3.3.3#创建多个集群节点实例
mkdir -p /data/700{0..5}/
#实例01节点配置信息(主库)
cat >/data/7000/redis.conf <<EOF
port 7000
daemonize yes
pidfile /data/7000/redis.pid
loglevel notice
logfile "/data/7000/redis.log"
dbfilename dump.rdb
dir /data/7000
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
#实例02节点配置信息(主库)
cat >/data/7001/redis.conf <<EOF
port 7001
daemonize yes
pidfile /data/7001/redis.pid
loglevel notice
logfile "/data/7001/redis.log"
dbfilename dump.rdb
dir /data/7001
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
#实例03节点配置信息(主库)
cat >/data/7002/redis.conf <<EOF
port 7002
daemonize yes
pidfile /data/7002/redis.pid
loglevel notice
logfile "/data/7002/redis.log"
dbfilename dump.rdb
dir /data/7002
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
#实例04节点配置信息(从库)
cat >/data/7003/redis.conf <<EOF
port 7003
daemonize yes
pidfile /data/7003/redis.pid
loglevel notice
logfile "/data/7003/redis.log"
dbfilename dump.rdb
dir /data/7003
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
#实例05节点配置信息(从库)
cat >/data/7004/redis.conf <<EOF
port 7004
daemonize yes
pidfile /data/7004/redis.pid
loglevel notice
logfile "/data/7004/redis.log"
dbfilename dump.rdb
dir /data/7004
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
#实例06节点配置信息(从库)
cat >/data/7005/redis.conf <<EOF
port 7005
daemonize yes
pidfile /data/7005/redis.pid
loglevel notice
logfile "/data/7005/redis.log"
dbfilename dump.rdb
dir /data/7005
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
#启动各节点
redis-server /data/7000/redis.conf
redis-server /data/7001/redis.conf
redis-server /data/7002/redis.conf
redis-server /data/7003/redis.conf
redis-server /data/7004/redis.conf
redis-server /data/7005/redis.conf
#检查是否启动
[root@db ~]# ps -ef|grep redis
root 27618 1 0 01:31 ? 00:00:00 redis-server *:7000 [cluster]
root 27624 1 0 01:31 ? 00:00:00 redis-server *:7001 [cluster]
root 27630 1 0 01:31 ? 00:00:00 redis-server *:7002 [cluster]
root 27636 1 0 01:31 ? 00:00:00 redis-server *:7003 [cluster]
root 27642 1 0 01:31 ? 00:00:00 redis-server *:7004 [cluster]
root 27648 1 0 01:31 ? 00:00:00 redis-server *:7005 [cluster]
#构建redis集群
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
#旧版本(redis<5.0):redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
#检查
redis-cli -p 7000 cluster nodes|grep master
redis-cli -p 7000 cluster nodes|grep slave
-----------------分割线----------------------------------
创建新的节点,扩容集群的redis实例
#创建新节点目录
mkdir -p /data/{7006..7007}/
#新节点配置文件
cat >/data/7006/redis.conf <<EOF
port 7006
daemonize yes
pidfile /data/7006/redis.pid
loglevel notice
logfile "/data/7006/redis.log"
dbfilename dump.rdb
dir /data/7006
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >/data/7007/redis.conf <<EOF
port 7007
daemonize yes
pidfile /data/7007/redis.pid
loglevel notice
logfile "/data/7007/redis.log"
dbfilename dump.rdb
dir /data/7007
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
#启动新节点
redis-server /data/7006/redis.conf
redis-server /data/7007/redis.conf
#添加新节点
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
#扩容添加新的主节点
redis-cli -p 7000 cluster nodes|grep master
[root@db53 ~]#redis-cli --cluster reshard 127.0.0.1:7000
How many slots do you want to move (from 1 to 16384)? 384 #要移动的槽位
What is the receiving node ID? 1d9605bc225d8175df2bc2299f5deaf0f72beb3a #接收槽位的节点ID
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: ffd4c5984ebf3443abcfc8cfc891050a1557a36a
Source node #2: done
#要均分这384个槽位,可指定多个源节点ID,done后分担这些节点压力;
#从所有其他主节点(7000/7001/7002)均分这 384 个槽位直接写all
#再次检查主节点
redis-cli -p 7000 cluster nodes|grep master
#把 127.0.0.1:7007 节点加入到以 127.0.0.1:7000 为入口的 Redis 集群中,并指定它作为ID为 1d9605bc... 的主节点(对应你的 7006 节点)的从节点。
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7000 --cluster-slave --cluster-master-id 1d9605bc225d8175df2bc2299f5deaf0f72beb3a #注意修改对应7006节点ID
#检查从节点
redis-cli -p 7000 cluster nodes|grep slave
#集群节点缩容管理
redis-cli --cluster reshard 127.0.0.1:7000
redis-cli --cluster del-node 127.0.0.1:7006 7b35495d269e8bcb1e6acbf71fe842ca28ecbf29
redis-cli --cluster del-node 127.0.0.1:7007 c49eafcf4c5b82c06083dfaf2194879f2cdd31ca
文档型数据库服务应用-mongodb
mongodb介绍(还未补充)
mongodb安装部署
#将软件包上传到系统
tar xf mongodb-linux-x86_64-rhel70-4.2.24.tgz -C /usr/local/
cd /usr/local/
#创建软链接
ln -s mongodb-linux-x86_64-rhel70-4.2.24/ mongodb
#配置环境变量
cat >> /etc/profile << EOF
export PATH="$PATH:/usr/local/mysql/bin:/usr/local/mongodb/bin:/usr/local/redis/src/"
EOF
source /etc/profile
#检查
[root@db53 local]# mongo
MongoDB shell version v4.2.24
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
#启动mongodb服务
mkdir -p /mongodb/conf
mkdir -p /mongodb/log
mkdir -p /mongodb/data
#编写配置文件
vim /mongodb/conf/mongo.conf
systemLog:
destination: file
path: "/mongodb/log/mongodb.log" #日志存储位置
logAppend: true #日志以追加模式记录
storage:
journal:
enabled: true
dbPath: "/mongodb/data" #数据路径的位置
processManagement:
fork: true #后台守护进程
pidFilePath: "/mongodb/data/mongo.pid" #pid文件的位置,一般不用配置,可以去掉这行,自动生成到data中
net:
port: 27017 #端口号,默认不配置端口号,是27017
bindIp: 10.0.0.53,127.0.0.1 #监听地址注意修改
security:
authorization: enabled #是否打开用户名密码验证
#启动
mongod -f /mongodb/conf/mongo.conf
#进入mongodb
mongo
mongodb的应用(操作命令)
基础库 / 集合(表)操作
数据库(db)核心操作
集合(表)核心操作
文档(行)CRUD 核心命令
插入(Create)
查询(Read)
更新(Update)
删除(Delete)
常用函数 / 操作符
条件操作符(查询 / 更新)
更新操作符
聚合函数(Aggregation)
管理类常用命令
基础管理(远程管理 用户权限管理)
#管理员用户创建
> use admin (验证库)
switched to db admin
> db.createUser(
{
user: "xiaoA",
pwd: "123456",
roles: [ { role: "root", db: "admin" } ]
}
)
#管理员登录连接数据库
mongo -uxiaoA -p123456 admin
mongo -uxiaoA -p123456 10.0.0.53:27017/admin
#普通用户创建
use oldboy
db.createUser({
user: "xiaoB",
pwd: "123456",
roles: [{role: "readWrite", db: "oldboy"}]
})
#普通用户登录连接数据库
mongo -uxiaoB -p123456 oldboy
mongo -uxiaoB -p123456 10.0.0.53:27017/oldboy
#查看用户信息
use admin
db.system.users.find().pretty()
#删除用户信息
use admin
db.dropUser("xiaoB")
mongodb主从架构
步骤一:创建主从同步数据库实例 (28017 -- 主节点 28018 29019 -- 从节点)
mkdir -p /mongodb/28017/conf /mongodb/28017/data /mongodb/28017/log
mkdir -p /mongodb/28018/conf /mongodb/28018/data /mongodb/28018/log
mkdir -p /mongodb/28019/conf /mongodb/28019/data /mongodb/28019/log
cat > /mongodb/28017/conf/mongod.conf << EOF
systemLog:
destination: file
path: "/mongodb/28017/log/mongodb.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "/mongodb/28017/data"
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
processManagement:
fork: true
net:
port: 28017
bindIp: 10.0.0.51,127.0.0.1
replication:
oplogSizeMB: 2048 -- 定义oplog日志存储量,实质是数据库服务的表的大小,因为同步用的日志存储在表中
replSetName: my_repl -- 表示复制集的名称,要和后面创建的集群名称一致
-- 表示设置复制集功能
EOF
cp /mongodb/28017/conf/mongod.conf /mongodb/28018/conf/
cp /mongodb/28017/conf/mongod.conf /mongodb/28019/conf/
sed -i 's#28017#28018#g' /mongodb/28018/conf/mongod.conf
sed -i 's#28017#28019#g' /mongodb/28019/conf/mongod.conf
mongod -f /mongodb/28017/conf/mongod.conf
mongod -f /mongodb/28018/conf/mongod.conf
mongod -f /mongodb/28019/conf/mongod.conf
步骤二:激活主从同步功能
mongo --port 28017 admin
config = {_id: 'my_repl', members: [
{_id: 0, host: '10.0.0.53:28017',priority:10},
{_id: 1, host: '10.0.0.53:28018'},
{_id: 2, host: '10.0.0.53:28019'}]
}
> rs.initiate(config)
{ "ok" : 1 }
步骤三:主从同步状态检查
my_repl:PRIMARY> rs.status();
{
"set" : "my_repl",
"date" : ISODate("2026-01-05T12:06:59.463Z"),
"myState" : 1,
"term" : NumberLong(1),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"heartbeatIntervalMillis" : NumberLong(2000),
"majorityVoteCount" : 2,
"writeMajorityCount" : 2,
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1767614810, 1),
"t" : NumberLong(1)
},
"lastCommittedWallTime" : ISODate("2026-01-05T12:06:50.472Z"),
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1767614810, 1),
"t" : NumberLong(1)
},
"readConcernMajorityWallTime" : ISODate("2026-01-05T12:06:50.472Z"),
"appliedOpTime" : {
"ts" : Timestamp(1767614810, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1767614810, 1),
"t" : NumberLong(1)
},
"lastAppliedWallTime" : ISODate("2026-01-05T12:06:50.472Z"),
"lastDurableWallTime" : ISODate("2026-01-05T12:06:50.472Z")
},
"lastStableRecoveryTimestamp" : Timestamp(1767614780, 4),
"lastStableCheckpointTimestamp" : Timestamp(1767614780, 4),
"electionCandidateMetrics" : {
"lastElectionReason" : "electionTimeout",
"lastElectionDate" : ISODate("2026-01-05T12:06:20.393Z"),
"electionTerm" : NumberLong(1),
"lastCommittedOpTimeAtElection" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"lastSeenOpTimeAtElection" : {
"ts" : Timestamp(1767614769, 1),
"t" : NumberLong(-1)
},
"numVotesNeeded" : 2,
"priorityAtElection" : 10,
"electionTimeoutMillis" : NumberLong(10000),
"numCatchUpOps" : NumberLong(0),
"newTermStartDate" : ISODate("2026-01-05T12:06:20.459Z"),
"wMajorityWriteAvailabilityDate" : ISODate("2026-01-05T12:06:21.903Z")
},
"members" : [
{
"_id" : 0,
"name" : "10.0.0.53:28017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 107,
"optime" : {
"ts" : Timestamp(1767614810, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2026-01-05T12:06:50Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "could not find member to sync from",
"electionTime" : Timestamp(1767614780, 1),
"electionDate" : ISODate("2026-01-05T12:06:20Z"),
"configVersion" : 1,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : 1,
"name" : "10.0.0.53:28018",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 50,
"optime" : {
"ts" : Timestamp(1767614810, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1767614810, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2026-01-05T12:06:50Z"),
"optimeDurableDate" : ISODate("2026-01-05T12:06:50Z"),
"lastHeartbeat" : ISODate("2026-01-05T12:06:58.547Z"),
"lastHeartbeatRecv" : ISODate("2026-01-05T12:06:57.995Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "10.0.0.53:28017",
"syncSourceHost" : "10.0.0.53:28017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 1
},
{
"_id" : 2,
"name" : "10.0.0.53:28019",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 50,
"optime" : {
"ts" : Timestamp(1767614810, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1767614810, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2026-01-05T12:06:50Z"),
"optimeDurableDate" : ISODate("2026-01-05T12:06:50Z"),
"lastHeartbeat" : ISODate("2026-01-05T12:06:58.547Z"),
"lastHeartbeatRecv" : ISODate("2026-01-05T12:06:57.995Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "10.0.0.53:28017",
"syncSourceHost" : "10.0.0.53:28017",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 1
}
],
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1767614810, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1767614810, 1)
}
步骤四:主从同步故障节点切换测试
mongod -f /mongodb/28017/conf/mongod.conf --shutdown
rs.status();备份恢复
两种类型的备份恢复工具应用场景区别:
类型一:(mongoexport/mongoimport)
异构平台迁移,比如:mysql <---> mongodb
相同平台迁移,比如:跨版本迁移 mongodb 2 ---> mongodb 3
类型二:(mongodump/mongorestore)
日常数据信息备份保存使用;
日常数据信息恢复修复使用;
数据库逻辑备份恢复
数据导出工具:mongoexport
工具使用常用参数信息:mongoexport --help
数据导入工具:mongoimport
工具使用常用参数信息:mongoimport --help
我现在的库是空的,需要先创建一些数据,模拟数据库数据
mongod -f /mongodb/conf/mongo.conf
#登录mongo
mongo -uxiaoA -p123456 admin
# 数据录入
for(i=0;i<10000;i++){db.log.insert({"uid":i,"name":"mongodb","age":6,"date":new Date()})}
-----------------------------------------------------------
备份
#单表备份至json格式(备份文件的名字可以自定义,默认导出了JSON格式的数据)
mongoexport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log -o /mongodb/log.json
#单表备份至csv格式(如果需要导出csv格式的数据,则需要使用 type=csv参数信息)
mongoexport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log --type=csv -f uid,name,age,date -o /mongodb/log.csv
#恢复json格式表数据到数据库log1
mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log1 /mongodb/log.json
#如果导入的表已经存在,可以在导入命令中加入 drop参数,将源表删除在导入(危险)
mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log1 --drop /mongodb/log.json
# 查看测试导入数据信息
[mongod@xiaoq ~]$ mongo -uroot -proot123 admin
> use oldboy
switched to db oldboy
> show tables
log
log1
> db.log1.find()
{ "_id" : ObjectId("6692db7839718e33da3c12e4"), "uid" : 0, "name" : "mongodb", "age" : 6, "date" : ISODate("2024-07-13T19:54:32.081Z") }
{ "_id" : ObjectId("6692db7839718e33da3c12e5"), "uid" : 1, "name" : "mongodb", "age" : 6, "date" : ISODate("2024-07-13T19:54:32.167Z") }
...
--------------------------------------------------------------
#恢复csv格式表数据到log2/log3
# csv格式的文件头行,有列名称信息
mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log2 --type=csv --headerline --file /mongodb/log.csv
-- headerline参数表示指定第一行是列名,不需要导入
# csv格式的文件头行,无列名称信息
mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldboy -c log3 --type=csv -f uid,name,age,date --file /mongodb/log.csv
工具使用常用参数信息:mongoexport --help
工具使用常用参数信息:mongoimport --help
数据库物理备份恢复
数据导出工具:mongodump/mongorestore
#实现全库数据信息备份
mkdir /mongodb/backup
mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -o /mongodb/backup
#实现单库数据信息备份
mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -d world -o /mongodb/backup/
#实现单表数据信息备份
mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -d world -c log -o /mongodb/backup/
#实现数据信息压缩备份
mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -o /mongodb/backup --gzip
mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -d world -o /mongodb/backup/ --gzip
mongodump -uroot -proot123 --port 27017 --authenticationDatabase admin -d world -c log -o /mongodb/backup/ --gzip
实现单库数据信息恢复
#恢复不存在的数据信息
mongorestore -uroot -proot123 --port 27017 --authenticationDatabase admin -d world1 /mongodb/backup/world
#进行覆盖恢复数据信息
mongorestore -uroot -proot123 --port 27017 --authenticationDatabase admin -d world1 ---drop /mongodb/backup/world
实现单表数据信息恢复
#恢复不存在的数据信息
mongorestore -uroot -proot123 --port 27017 --authenticationDatabase admin -d world1 -c t1 /mongodb/backup/world/city.bson
mongorestore -uroot -proot123 --port 27017 --authenticationDatabase admin -d world1 -c t1 --gzip /mongodb/backup/world/city.bson.gz
工具使用常用参数信息:
数据库高可用集群方案MGR(全同步)
MySQL Group Replication(MGR)是官方原生的高可用集群方案,支持单主 / 多主模式
高可用:多节点互备,单节点挂不影响集群;
自动选主 + 数据强一致,切换无数据丢失;
高性能:可横向扩容节点,分担读写流量。
抗雪崩:结合 nginx限制单节点QPS、proxySQL、Redis
部署流程(单主模式,1 主 2 从)
读写分离:主节点写入,从节点读,实现负载均衡
#系统环境优化
# 1. 关闭防火墙/SELinux(生产可按需放行端口)
systemctl stop firewalld && systemctl disable firewalld
setenforce 0 && sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 2. 时间同步(MGR对时间一致性要求高)
yum install -y chrony
systemctl start chronyd && systemctl enable chronyd
chronyc syncronize
# 3. 关闭swap(避免内存交换影响性能)
swapoff -a && sed -i '/swap/s/^/#/' /etc/fstab
# 4. 调整系统文件描述符限制
echo "* soft nofile 65535" >> /etc/security/limits.conf
echo "* hard nofile 65535" >> /etc/security/limits.conf
ulimit -n 65535
#mysql配置
# 1. 确认MySQL 8.0版本
/usr/local/mysql/bin/mysql -V
# 输出示例:mysql Ver 8.0.35 for Linux on x86_64 (MySQL Community Server - GPL)
# 2. 启动MySQL并设为开机自启
systemctl start mysqld3306.service && systemctl enable mysqld3306.service
# 3. 登录MySQL(初始密码/自定义密码)
mysql -uroot -p -S /tmp/mysql3306.sockvim /data/3306/my.cnf
[mysqld]
# 基础必选配置
server_id = 51 # 每个节点唯一:51/52/53
datadir = /data/3306/data
socket = /tmp/mysql3306.sock
port = 3306
basedir = /usr/local/mysql
log_error = /data/3306/logs/error.log
# MGR核心依赖配置(所有节点一致)
gtid_mode = ON # 必须开启GTID
enforce_gtid_consistency = ON # 强制GTID一致性
master_info_repository = TABLE # 主从信息存表(替代文件)
relay_log_info_repository = TABLE # 中继日志信息存表
binlog_checksum = NONE # 关闭binlog校验(MGR要求)
log_slave_updates = ON # 从库记录binlog(用于同步)
binlog_format = ROW # 行格式binlog(MGR唯一支持)
transaction_write_set_extraction = XXHASH64 # MGR用于冲突检测的哈希算法
loose-group_replication_bootstrap_group = OFF # 仅引导节点临时开启
loose-group_replication_start_on_boot = OFF # 开机不自动启动MGR
loose-group_replication_ssl_mode = REQUIRED # 加密通信(生产推荐)
loose-group_replication_recovery_use_ssl = 1
# MGR个性配置(每个节点不同)
loose-group_replication_group_name = "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee" # 自定义UUID(所有节点一致)
loose-group_replication_local_address = "10.0.0.51:33061" # 本节点IP+MGR通信端口(51/52/53对应修改)
loose-group_replication_group_seeds = "10.0.0.51:33061,10.0.0.52:33061,10.0.0.53:33061" # 所有节点的MGR通信地址(所有节点一致)
loose-group_replication_single_primary_mode = ON # 单主模式(推荐,避免多主写入冲突)
loose-group_replication_enforce_update_everywhere_checks = OFF # 单主模式设为OFF
#其它优化
innodb_buffer_pool_size = 物理内存的50%-70% # 如64G内存设为40G
innodb_log_file_size = 4G # 增大redo日志,减少刷盘
group_replication_flow_control_mode = QUOTA # 流量控制,避免高并发下集群拥堵
group_replication_member_weight = 50 # 选举权重(数值大的节点优先成为主)
---------------------------------------------------------------------------------
注意:server_id、loose-group_replication_local_address 需按节点修改(51 节点改 51,52 改 52);
配置完成后重启所有节点 MySQL:systemctl restart mysqld3306.service。步骤 1:所有节点创建 MGR 复制用户
登录每个节点的 MySQL,创建 MGR 专用复制用户(权限最小化):
-- 所有节点执行
CREATE USER rpl_user@'%' IDENTIFIED WITH mysql_native_password BY '123456';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
FLUSH PRIVILEGES;
-- 配置MGR复制通道(所有节点执行)
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='123456' FOR CHANNEL 'group_replication_recovery';
步骤 2:初始化引导节点(10.0.0.51)
仅在第一个节点执行,引导集群启动:
-- 1. 加载MGR插件(所有节点都要加载,先在引导节点执行)
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
-- 2. 验证插件加载成功
SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME = 'group_replication';
-- 输出PLUGIN_STATUS=ACTIVE则正常
-- 3. 引导集群启动(仅引导节点执行,执行后立即改回OFF)
SET GLOBAL group_replication_bootstrap_group = ON;
-- 4. 启动MGR集群
START GROUP_REPLICATION;
-- 5. 关闭引导模式(关键!否则其他节点无法加入)
SET GLOBAL group_replication_bootstrap_group = OFF;
-- 6. 验证引导节点状态(确认加入集群)
SELECT MEMBER_ID, MEMBER_HOST, MEMBER_STATE FROM performance_schema.replication_group_members;
-- 输出MEMBER_STATE=ONLINE,仅显示当前节点(51)
步骤 3:加入其他节点(52、53)
在 10.0.0.52、10.0.0.53 节点执行以下操作:
-- 1. 加载MGR插件(和引导节点一致)
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
-- 2. 启动MGR,自动加入集群
START GROUP_REPLICATION;
-- 3. 验证节点状态(所有节点执行,确认3个节点都ONLINE)
SELECT MEMBER_ID, MEMBER_HOST, MEMBER_ROLE, MEMBER_STATE FROM performance_schema.replication_group_members;
#正常输出示例:
MEMBER_ID MEMBER_HOST MEMBER_ROLE MEMBER_STATE
990263c1-e486-11f0-80cf-000c29f08bc6 10.0.0.51 PRIMARY ONLINE
a0e263c1-e486-11f0-80cf-000c29f08bc7 10.0.0.52 SECONDARY ONLINE
b1f263c1-e486-11f0-80cf-000c29f08bc8 10.0.0.53 SECONDARY ONLINE
PRIMARY:主节点(可读写),SECONDARY:从节点(只读),符合单主模式预期。方案 1:VIP+Keepalived(推荐,应用无感知)
在 3 个 MGR 节点部署 Keepalived,将 VIP 绑定到PRIMARY节点;
应用只需连接 VIP(如 10.0.0.100),主节点故障后,MGR 自动选新主,Keepalived 将 VIP 飘到新主,应用无感知。
方案 2:ProxySQL(适配高访问量,读写分离)
ProxySQL 可自动识别 MGR 的PRIMARY/SECONDARY节点,实现:
写操作(INSERT/UPDATE/DELETE)自动路由到PRIMARY节点;
读操作(SELECT)负载均衡到所有SECONDARY节点;
主节点故障后,ProxySQL 自动识别新主,无需人工干预。
-------------------------------------------------------------------------------------
读写分离配置(ProxySQL 示例)
登录 ProxySQL 管理端,添加 MGR 节点并配置规则:
-- 1. 添加3个MGR节点到ProxySQL(主节点hostgroup=10,从节点=20)
INSERT INTO mysql_servers (hostgroup_id, hostname, port, weight) VALUES (10, '10.0.0.51', 3306, 1);
INSERT INTO mysql_servers (hostgroup_id, hostname, port, weight) VALUES (20, '10.0.0.52', 3306, 10);
INSERT INTO mysql_servers (hostgroup_id, hostname, port, weight) VALUES (20, '10.0.0.53', 3306, 10);
-- 2. 配置MGR自动识别主从(ProxySQL 2.0+支持)
INSERT INTO mysql_replication_hostgroups (writer_hostgroup, reader_hostgroup, comment) VALUES (10, 20, 'MGR读写分离');
-- 3. 配置SQL规则:写操作走主库,读操作走从库
INSERT INTO mysql_query_rules (rule_id, active, match_pattern, destination_hostgroup, apply)
VALUES (1, 1, '^SELECT.*FOR UPDATE$', 10, 1); -- 带锁SELECT走主库
INSERT INTO mysql_query_rules (rule_id, active, match_pattern, destination_hostgroup, apply)
VALUES (2, 1, '^SELECT', 20, 1); -- 普通SELECT走从库
-- 4. 加载配置并保存
LOAD MYSQL SERVERS TO RUNTIME;
SAVE MYSQL SERVERS TO DISK;
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;
应用连接 ProxySQL 的 6033 端口即可实现自动读写分离 + 故障切换。
-------------------------------------------------------------------
接入层限流:用 Nginx/API 网关(如 Kong)限制 QPS,避免瞬间流量打满备节点:
# Nginx配置示例:单IP每秒最多100请求
limit_req_zone $binary_remote_addr zone=mysql:10m rate=100r/s;
limit_req zone=mysql burst=20 nodelay;
延迟队列:非核心写操作(如日志、统计)放入 MQ(RabbitMQ/Kafka),避免同步写压垮数据库。
缓存层面:减少数据库直查
热点数据缓存:用 Redis 缓存高频查询(如商品详情、用户信息),命中率≥90% 可大幅降低数据库读压力;
缓存预热:切换前提前预热备节点的缓存(比如批量加载热点数据到 Redis),避免切换后缓存穿透打满数据库。
数据库层面:优化配置 + 扩容
备节点资源扩容:备节点 CPU / 内存 / 磁盘 IO 不低于主节点(高访问量下备节点需扛全量读 + 临时写);
连接池优化:限制数据库最大连接数(避免连接数打满),应用层用连接池(如 Druid):
# MySQL配置:最大连接数设为合理值(如1000,根据服务器配置)
max_connections = 1000
wait_timeout = 60 # 闲置连接超时释放
读写分离升级:从「一主一从」改为「一主多从」,ProxySQL 自动负载均衡读流量到多个从节点,单个从节点压力降低。
切换层面:平滑切换 + 预热
切换前预热备节点:提前将备节点设为「只读 + 分担部分读流量」,让备节点先适应流量,避免切换后瞬间满负载;
渐进式切换:用 ProxySQL 逐步将流量切到备节点(比如先切 10%→50%→100%),而非一次性切换。
存储层面:分库分表(大规模场景)
高访问量下单库单表性能瓶颈明显,用 Sharding-JDBC/MyCat 分库分表,将数据分散到多个主从集群,单个集群故障不影响整体,彻底避免雪崩。监控集群状态:
-- 1. 查看集群成员状态(所有节点ONLINE才正常)
SELECT * FROM performance_schema.replication_group_members;
-- 2. 查看主节点角色(确认PRIMARY节点)
SELECT MEMBER_HOST, MEMBER_ROLE FROM performance_schema.replication_group_members WHERE MEMBER_ROLE='PRIMARY';
-- 3. 查看MGR错误日志(故障排查)
tail -100 /data/3306/logs/error.log | grep -i group_replication

评论交流
欢迎留下你的想法